Posts filed under ‘matemática’
O Problema dos Três Corpos: Uma Dança Gravitacional Complexa
Muita gente deve ter ficado curiosa ao assistir à série “O problema dos 3 corpos” da Netflix e de ve ter ficado intrigada sobre o problema real que dá nome à serie (e à série de livros) que é de origem astronômica. Fato é que o universo é repleto de fenômenos fascinantes e desafiadores, e um dos mais intrigantes, sem dúvida, é o Problema dos Três Corpos.
O problema: Imagine três corpos celestes, como planetas ou estrelas, orbitando uns aos outros sob a influência de suas próprias forças gravitacionais. O movimento desses corpos é regido pelas leis da física, especialmente pela Lei da Gravitação Universal de Newton. No entanto, mesmo com essas leis bem estabelecidas, o Problema dos Três Corpos desafia nossa capacidade de prever com precisão o comportamento dos componentes do sistema.
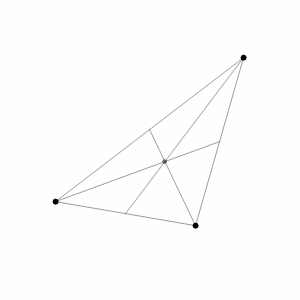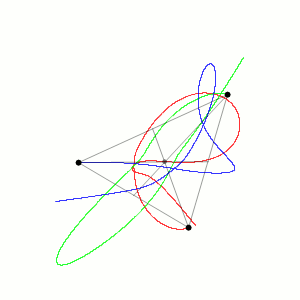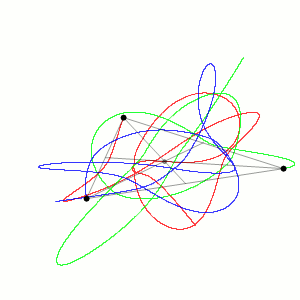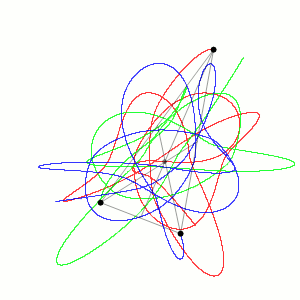
O problema dos 3 corpos foi originalmente proposto por Isaac Newton em 1687. Ele foi capaz de encontrar soluções analíticas para o caso especial de três corpos que estão em uma configuração triangular. No entanto, o problema geral de três corpos não foi resolvido analiticamente até o século 20.
Vamos considerar um exemplo simplificado do Problema dos Três Corpos, onde temos três corpos de massa igual, denominados A, B e C, que interagem entre si apenas pela força gravitacional.
As equações diferenciais que descrevem o movimento de cada corpo podem ser expressas usando as Leis de Newton da Gravitação Universal:
Para o corpo A:
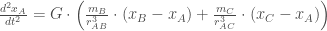
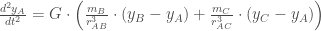
Onde:
é a constante gravitacional,
e
são as massas dos corpos B e C, respectivamente,
,
e
são as coordenadas cartesianas dos corpos A, B e C, respectivamente, e
e
são as distâncias entre os corpos A e B, e A e C, respectivamente.
As equações para os corpos B e C são análogas.
Para resolver numericamente essas equações e prever o movimento dos corpos ao longo do tempo, podemos usar métodos como o método de Euler ou o método de Runge-Kutta.
No entanto, devido à natureza não linear do problema e à sensibilidade às condições iniciais, a previsão a longo prazo do movimento dos corpos pode se tornar imprecisa, especialmente para sistemas complexos ou instáveis. Portanto, simulações computacionais detalhadas são frequentemente necessárias para entender o comportamento dos sistemas de três corpos.
Uma das principais razões para a dificuldade do problema é sua grandiosa complexidade matemática. As equações que descrevem o movimento dos corpos são altamente não lineares e não têm solução analítica para o caso geral (n-corpos). Isso significa que não há uma fórmula matemática simples que possa prever o movimento dos corpos ao longo do tempo. Em vez disso, os cientistas precisam recorrer a métodos numéricos e simulações por computador para estudar o problema.
Além da complexidade matemática, o Problema dos Três Corpos exibe comportamento caótico e é altamente sensível às condições iniciais. Isso significa que pequenas variações nas posições ou velocidades iniciais dos corpos podem levar a resultados significativamente diferentes ao longo do tempo. Essa sensibilidade dificulta ainda mais a previsão precisa do movimento dos corpos.
Embora o Problema dos Três Corpos seja desafiador, ele tem amplas aplicações em diversas áreas da ciência, incluindo astronomia, física e engenharia espacial. O estudo desse problema nos ajuda a entender melhor o comportamento dos sistemas gravitacionais complexos no universo e pode fornecer insights importantes para o desenvolvimento de futuras missões espaciais.
O Problema dos Três Corpos continua sendo um dos desafios mais intrigantes e complexos da física. Apesar de sua dificuldade, os cientistas continuam a explorar e estudar esse problema, utilizando métodos avançados de computação e simulação para desvendar os segredos da dança gravitacional dos corpos celestes no universo.
Em uma simulação, em python disponível no Github (em 2D) podemos ver o seguinte gráfico do movimento dos 3 corpos:

O que confirma o movimento caótico dos corpos a partir das condições iniciais.
SOBRE A SÉRIE: A série da Netflix é uma adpatação do romance homônimo de Liu Cixin, que ganhou o Prêmio Hugo de Melhor Romance em 2015. O livro conta a história de uma astrofísica chinesa que se envolve em uma investigação secreta relacionada ao problema dos 3 corpos e à possível invasão da Terra por uma civilização alienígena. Na minha opinião, vale a audiência de quem, como eu, curte ficção científica.
segunda-feira, 25 março, 2024 at 1:59 pm Deixe um comentário
Recursividade: a multiplicação recursiva, as definições matemáticas por indução/recursão e os axiomas de Peano
A recursividade, como já vimos anteriormente deve primeiro sempre ser pensada nos casos mais simples (os casos bases ou casos básicos). Vamos ver um exemplo para nos ajudar.
É possível, por exemplo, definir a multiplicação de dois números inteiros m e n, sendo n > 0, em termos da operação de adição. O caso mais simples dessa operação é aquele no qual n = 0. Nesse caso, o resultado da operação é igual a 0, independentemente do valor de m. De acordo com a idéia exposta acima, precisamos agora pensar em como podemos expressar a solução desse problema no caso em que n > 0, supondo que sabemos determinar sua solução para casos mais simples, que se aproximam do caso básico. Neste caso, podemos expressar o resultado de m × n em termos do resultado da operação, mais simples m × (n − 1); ou seja, podemos definir m × n como sendo igual a m + (m × (n − 1)),
para n > 0. Ou seja, a operação de multiplicação pode então ser definida indutivamente pelas seguintes equações:
,
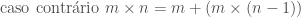
Uma maneira alternativa de pensar na solução desse problema seria pensar na operação de multiplicação m * n como a repetição, n vezes, da operação de adicionar m, isto é:
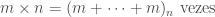
Raciocínio análogo pode ser usado para expressar a operação de exponenciação, com expoente inteiro não-negativo, em termos da operação de multiplicação (que será visto em outro post).

O programa a seguir apresenta, na linguagem C, uma forma computar o resultado da multiplicação de dois números, dados como argumentos dessas operações de forma recursiva. As função multiplica é definida usando-se chamadas à própria função, razão pela qual ela é chamada de recursiva.
int multiplica(int num1, int num2){
//multiplicação por zero
if (num1 == 0 || num2 == 0) {
return 0;
}
//caso base, onde a recursão para:
else if (num2 == 1) {
return num1;
}
//multiplicando através da soma com recursividade:
else {
return (num1 + multiplica(num1,num2 - 1));
}
}
Considere a função multiplica definida acima. A sua definição espelha diretamente a definição recursiva da operação de multiplicação, em termos da adição, apresentada anteriormente. Ou seja, multiplicar m por n (onde n é um inteiro não-negativo) fornece:
-
0, no caso base (isto é, sen==0); m + multiplica(m, n-1), no caso indutivo/recursivo (isto é,se n!=0).
Vejamos agora, mais detalhadamente, a execução de uma chamada multiplica(3,2). Cada chamada da função multiplica cria novas variáveis, de nome m e n. Existem, portanto, várias variáveis com nomes (m e n), devido às chamadas recursivas. Nesse caso, o uso do nome refere-se à variável local ao corpo da função que está sendo executado. As execuções das chamadas de funções são feitas, dessa forma, em uma estrutura de pilha. Chamamos, genericamente, de estrutura de pilha uma estrutura na qual a inserção (ou alocação) e a retirada (ou liberação) de elementos é feita de maneira que o último elemento inserido é o primeiro a ser retirado.
Em resumo, na tabela abaixo, representamos a estrutura de pilha criada pelas chamadas à função multiplica. Os nomes m e n referem-se, durante a execução, às variáveis mais ao topo dessa estrutura. Uma chamada recursiva que vai começar a ser executada está indicada por um negrito. Nesse caso, o resultado da expressão, ainda não conhecido, é indicado por “…”.
Tabela 4.2: Passos na execução de multiplica(3,2) |
| Comando/Expressão | Resultado (expressão) | Estado (após execução/avaliação) |
multiplica(3,2) … | m↦ 3n↦ 2 | |
n == 0 | falso | m↦ 3n↦ 2 |
return m + multiplica(m,n-1) | … | m↦ 3 m↦ 3n↦ 2 n↦ 1 |
n == 0 | falso | m↦ 3 m↦ 3n↦ 2 n↦ 1 |
return m + multiplica(m,n-1) | … | m↦ 3 m↦ 3 m↦ 3n↦ 2 n↦ 1 n↦ 0 |
n == 0 | verdadeiro | m↦ 3 m↦ 3 m↦ 3n↦ 2 n↦ 1 n↦ 0 |
return 0 | m↦ 3 m↦ 3n↦ 2 n↦ 1 | |
return m + 0 | m↦ 3n↦ 2 | |
return m + 3 | ||
multiplica(3,2) | 6 |
E assim vemos como o procedimento recursivo para multiplicar dois números funciona com um exemplo em linguagem C, facilmente portável para outra linguagem.
Agora, para uma visão matematicamente mais precisa, continue lendo…
Definições por indução
As definições por indução (usando o princípio da indução dos axiomas de Peano) se baseiam na possibilidade de se iterar uma função 
n, de vezes.
Mais precisamente, seja 


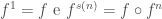


s(n) é o sucessor de um número natural n, conforme descrito nos axiomas de Peano).
Numa exposição mais, digamos, sistemática da teoria dos números naturais, a existência da n-ésima iterada 

É importante ressaltar que não é possível, nesta altura, definir 
n é, por enquanto, apenas um elemento do conjunto 
Admitamos assim que, dada uma função 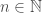
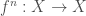
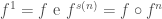
Agora, podemos ver um exemplo de definição por indução (recursão) usando o que acabamos de ver, as iteradas da função 
O produto, a multiplicação, de dois números naturais é definido da seguinte forma:
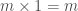

Em outras palavras: multiplicar um número 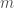


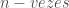
Assim, por exemplo, 
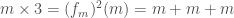
Lembrando a definição de 

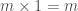

Que é exatamente a mesma definição recursiva que vimos acima!
Fermat, o cálculo integral, quadraturas de curvas e comunicação acadêmica
É lugar-comum que o Cálculo Diferencial e Integral foi “descoberto” simultânea e independentemente por Isaac Newton (1643-1727) e Leibniz (1646-1716), individualmente, cada um a seu modo, diante de problemas semelhantes, mas com interpretações, definições e nomenclaturas totalmente diferentes. Newton, como físico, estava preocupado inicialmente com os problemas de taxas de variação do movimento e Leibiniz buscava algo mais, digamos, “abstrato” e puramente matemático (baseado no problema da tangente em pontos de curvas, ao fim e ao cabo o mesmo problema da taxa de variação). Newton chamava a variação (ou, modernamente, a derivada) de “fluxões” e sua nomenclatura não sobreviveu (a de Leibniz era muito mais robusta).
Poucos sabem, inclusive, que as primeiras edições do “Método das Fluxões” de Newton citava Leibniz e seu método. Após a controvérsia do cálculo, obviamente nas edições posteriores isso foi retirado. O fato é que, por conta da falta de comunicação acadêmica na época (méados do século XVII), muitos cientistas e matemáticos estiveram bem próximos de ter o “insight” do Cálculo diferencial e integral, ou seja, juntar todos os pontos e apresentar algo geral que funcionasse para outros problemas de variação e áreas (que foi o que Newton e Leibiniz fizeram, apresentaram métodos para o problema das taxas de variação (tangentes) e de áreas sob curvas que poderiam ser generalizados para outros problemas semelhantes).

Pierre de Fermat (1601-1665) foi um deles. Este post mostra o quão perto ele estava de apresentar uma gênese do cálculo integral. Precisamos, claro, de contexto. Se você não quer saber do contexto histórico pode pular a parte do contexto.
Vamos lá… O problema de encontrar a área de uma forma plana fechada é conhecido por quadratura. A palavra refere-se à própria natureza da problema: expressar a área em termos de unidades de área, que são quadrados. É um problema que remonta aos gregos antigos e diversos nomes são famosos pelas soluções aproximadas do problema, como Arquimedes (e seu método da exaustão). Mas os gregos não consideravam o infinito como o consideramos hoje (e os paradoxos de Zenão são uma prova disto).
Por volta de 1600, processos infinitos foram introduzidos na matemática e, então, o problema da quadratura tornou-se meramente computacional. O próprio círculo, por esta época, já estava bem definido em relação à sua quadratura (ou área
A hipérbole é a curva obtida quando um cone é cortado por um plano num ângulo maior do que o ângulo existente entre a base do cone e o seu lado (daí o prefixo “hiper” significando “em excesso de”). O cone (e o corte) sendo algo como a figura abaixo:

Como resultado deste corte, a hipérbole fica com dois “ramos” separados e simétricos. O resultado é a imagem abaixo:


Percebe-se, pela imagem acima que a hipérbole tem um par de linhas retas associadas a ela, suas duas linhas tangentes no infinito. Quando se move ao longo de cada “ramo”, afastando-se do centro, nos aproximamos cada vez mais destas linhas, mas nunca a alcançamos. Essas linhas são as assíntotas da hipérbole. São, grosso modo, a manifestação geométrica do conceito de limite, base do cálculo diferencial e integral.
Os gregos trabalhavam com as curvas de um ponto de vista puramente geométrico, mas a invenção da geometria analítica por Descartes (1596-1650) fez com que o estudo dessas curvas se tornassem cada vez mais parte da álgebra. No lugar da curva em si, considera-se, então, a equação que relaciona as coordenadas x e y de um ponto da curva.

Cada uma das seções cônicas é um caso especial de uma equação quadrática (de segundo grau), cuja forma geral é: 
Para o círculo, por exemplo, temos que 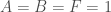


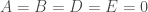
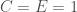

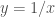
Finalizando o contexto, sabe-se que Arquimedes não conseguiu encontrar a quadratura da hipérbole pelo método da exaustão. Também o métodos dos indivisíveis não alcançou este objetivo, principalmente porque a hipérbole, ao contrário do círculo e da elipse, é uma curva que vai ao infinito, assim é preciso esclarecer o que queremos dizer por quadratura neste caso.
A figura abaixo mostra um ramo da hipérbole 

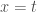
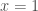
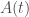
 a
a Vários matemáticos tentaram resolver este problema de forma independente (mais uma vez a falta de clareza na “comunicação acadêmica” – que sequer existia, atrapalhava a matemática e a ciência). Os mais destacados foram os já citados, Descartes e Fermat, além de Pascal (1623-1662). Os 3 são o grande triunvirato francês nos anos que antecederam a invenção do Cálculo infinitesimal (outro nome para o cálculo diferencial e integral). Fim do Contexto.
Fermat estava interessado na quadratura de curvas cuja equação geral é 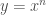
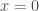
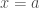
 através de uma série de retãngulos, cujas bases formam uma progressão geométrica
através de uma série de retãngulos, cujas bases formam uma progressão geométricaFermat, então, imaginou o intervalo entre 

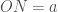
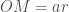

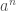


(1) 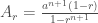
onde o r subscrito em A indica que a área ainda depende de nossa escolha de 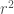

Para conseguir isso, a proporção comum r deve se aproximar de 1, e quanto mais próxima, melhor o “encaixe” (e mais fácil a soma). Aliás, quando r → 1 (r tende ao valor 1), a equação 1 torna-se a expressão indeterminada 0/0. Fermat foi capaz de contornar essa dificuldade notando que o denominador da equação 1 acima, 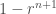
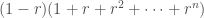
Quando o fator 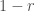
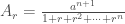
Quando deixamos r → 1, cada parcela no denominador tende a 1, o que resulta na fórmula
(2)
Todo estudante de cálculo vai reconhecer a equação 2 como a integral 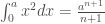

Fermat trabalhou nessa ideia em torno de 1640, cerca de 30 anos antes de Newton e Leibniz estabelecessem esta mesma fórmula como parte de seus respectivos cálculo diferencial e integral. Este trabalho representou MUITO porque conseguia a quadratura não apenas de uma curva, mas de toda uma família de curvas, aquelas fornecidas pela equação
Interessante notar que quando 
O mais incrível de tudo é que, ao modificar ligeiramente seu procedimento, Fermat mostrou que a equação 2 permanece válida mesmo quando n é um inteiro negativo , desde que agora calculemos a área de x = a (onde a > 0) até o infinito. Quando n é um inteiro negativo, digamos 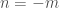
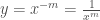

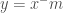
Fermat ficou muito contente com sua descoberta porque ela permanecia válida mesmo quando a restrição de n ser positivo era removida. Mas, havia um problema. problema. A fórmula de Fermat falhava para uma curva da qual toda a família deriva o seu nome: a hipérbole 
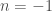


Quem resolveu este problema foi um dos contemporâneos de Fermat, embora pouco conhecido. Grégoire de Saint-Vicent (1584-1667), um jesuíta belga que trabalhou a maior parte da vida trabalhando em problemas de quadratura.
Seu principal trabalho, Opus geometricum quadraturae circuli et sectionum coni (1647), foi compilado a partir de milhares de textos científicos que Saint-Vincent deixou para trás quando fugiu de Praga ante o avanço dos suecos em 1631. Eles foram resgatados por um colega e devolvidos ao autor dez anos depois. O atraso na publicação torna difícil estabelecer a primazia de Saint-Vincent com certeza absoluta, mas parece que ele foi o primeiro a notar que, quando
A imagem abaixo mostra que que, conforme a distância de 0 cresce geometricamente, as áreas correspondentes crescem em incrementos iguais — ou seja, aritmeticamente — e isso continua sendo verdade mesmo ao passarmos ao limite quando r → 1 (ou seja, quando fazemos a transição dos retângulos discretos para a hipérbole contínua). Mas isso, por sua vez, implica que a relação entre a área e a distância é logarítmica. Mais precisamente, se denotarmos por A(t) a área sob a hipérbole, a partir de um ponto de referência fixo x > 0 (por conveniência geralmente escolhemos x = 1) até um ponto variável x = t, teremos A(t) = log t. Um dos alunos de Saint-Vincent, Alfonso Anton de Sarasa (1618-1667), escreveu essa relação explicitamente registrando uma das primeiras ocasiões em que se fez o uso de uma função logarítmica (que eram, prioritariamente, uma ferramenta usada para cálculos complexos).

Assim, a quadratura da hipérbole foi finalmente conseguida cerca de dois mil anos depois dos gregos, que primeiro enfrentaram o problema.
Portanto, quando Newton e Leibniz se debruçaram sobre os problemas que os levariam independepentemente à invenção da mais incrível e impressionante ferramenta científica de todos os tempos (o Cálculo diferencial e integral), as princiais ideias por trás do Cálculo já eram razoavelmente bem conhecidas pela comunidade matemática. O método dos indivisíveis, embora repousando em uma base incerta, tinha sido aplicado com sucesso a um conjunto de curvas e sólidos; e o método da exaustão de Arquimedes, em sua forma moderna, revisada, resolvera a quadratura da família de curvas
O ponto é que estas ferramentas teriam sido desenvolvidas, provavelmente, muito antecipadamente se existisse, à época, como hoje, uma comunidade científica vibrante e atuante, com publicações compartilhadas e o conhecimento sendo construído sobre as bases do que se fez anteriormente.
Problemas de comunicação e, principalmente, locomoção e transporte, claro, afetavam isso, mas a postura de cientistas, como Newton que guardavam para si seus trabalhos (ele só publicou o seu cálculo quando viu que o que Leibniz havia publicado era, ao fim e ao cabo, o mesmo que ele tinha conseguido), atrapalhavam bastante o avanço das contribuições.
O que teria acontecido (sabe-se que a revolução científica, de fato, começou com a invenção do cálculo e a normatização do método científico) se a comunicação acadêmica tivesse levado à invenção do cálculo alguns anos, décadas ou séculos antes do que o que realmente o foi?
…
Nunca saberemos. Mas, gosto de pensar que os avanços científicos teriam sido acelerados enormemente…
segunda-feira, 14 fevereiro, 2022 at 4:25 pm Deixe um comentário
Como calcular o custo de um algoritmo?
De forma rápida, existem duas formas de se calcular o custo de um algoritmo:
- Usando o cálculo de complexidade de tempo[1] (em que o custo é expresso por uma função que varia sobre o tamanho da entrada do algoritmo) e
- Usando o cálculo de complexidade de espaço (em que o custo é expresso por uma função que varia também sobre o espaço em memória, primária ou secundária, usado para finalizar o algoritmo).
A mais comum é calcular a complexidade de tempo ou através de uma função de custo associada ao algoritmo[2] ou à complexidade do pior caso expresso em termos da Notação Assintótica do pior caso[3] (que representa um limite superior[4] para o algoritmo).
Para se chegar à função de custo, normalmente se conta quantas instruções são executadas para o algoritmo para resolver um problema. A função de custa é expressa por um polinômio, em relação ao tamanho da entrada.
Por exemplo, no algoritmo
for(i=0; i<N; i++){
print(i);
}
poderíamos dizer que o tempo gasto é
T(N) =
N*(tempo gasto por uma comparação entre i e N) +
N*(tempo gasto para incrementar i) +
N*(tempo gasto por um print)
Isso daria, no caso, a função de custo T(N) em relação ao tamanho da entrada N.
Já a complexidade usando notação assintótica é, geralmente, mais usada para classes de algoritmos por conta da sua simplicidade e abstração. Siga o raciocínio:
Ao ver uma expressão como n+10 ou n²+1, a maioria das pessoas pensa automaticamente em valores pequenos de n. A análise de algoritmos faz exatamente o contrário: ignora os valores pequenos e concentra-se nos valores enormes de n. Para valores enormes de n, as funções n² , (3/2)n² , 9999n² , n²/1000 , n²+100n , etc. crescem todas com a mesma velocidade e portanto são todas equivalentes.
Esse tipo de matemática, interessado somente em valores enormes de n, é chamado comportamento assintótico[5]. Nessa matemática, as funções são classificadas em ordens[6] (como as ordens religiosas da Idade Média); todas as funções de uma mesma ordem são equivalentes. As cinco funções acima, por exemplo, pertencem à mesma ordem.
Essa ideia reflete que precisamos focar, na verdade, em quão rápido uma função cresce com o tamanho da entrada.(essa é a base da “análise de algoritmos” e o centro de como se calcular o custo de um algoritmo).
Nós chamamos isso de taxa de crescimento do tempo de execução. Para manter as coisas tratáveis, precisamos simplificar a função até evidenciar a parte mais importante e deixar de lado as menos importantes.
Por exemplo, suponha que um algoritmo, sendo executado com uma entrada de tamanho n, leve 6n²+100n+300 instruções de máquina. O termo 6n² torna-se maior do que os outros termos, 100n+300 uma vez que n torna-se grande o suficiente. A partir de 20 neste caso.
Abaixo temos um gráfico que mostra os valores de 6n² e 100n+300 para valores de n variando entre 0 e 100:
Podemos dizer que este algoritmo cresce a uma taxa n², deixando de fora o coeficiente 6 e os termos restantes 100n+300. Não é realmente importante que coeficientes usamos, já que o tempo de execução é an²+bn+c, para alguns números a>0, b, e c, sempre haverá um valor de n para o qual an² é maior que bn+c e essa diferença aumenta juntamente com n. Por exemplo, aqui está um gráfico mostrando os valores de 0,6n² e 1000n+3000 de modo que reduzimos o coeficiente de n² por um fator de 10 e aumentamos as outras duas constantes por um fator de 10:
O valor de n para o qual 0,6n² se torna maior que 1000n+3000 aumentou, mas sempre haverá um ponto de cruzamento, independentemente das constantes. E a partir deste valor de cruzamento, 0,6n² sempre crescerá mais rapidamente (e sempre será maior).
Descartando os termos menos significativos e os coeficientes constantes, podemos nos concentrar na parte importante do tempo de execução de um algoritmo — sua taxa de crescimento — sem sermos atrapalhados por detalhes que complicam sua compreensão. Quando descartamos os coeficientes constantes e os termos menos significativos, usamos notação assintótica. Usa-se, normalmente, três formas: notação Θ[7] , notação O[8] , notação Ω[9] .
Por exemplo, suponha que tenhamos nos esforçado bastante e descoberto que um certo algoritmo gasta tempo
T(N) = 10*N² + 137*N + 15Nesse caso o termo quadrático 10*N² é mais importante que os outros pois para praticamente qualquer valor de N ele irá dominar o total da soma. A partir de N ≥ 14 o termo quadrático já é responsável pela maioria do tempo de execução e para N > 1000 ele já é responsável por mais de 99%. Para fins de estimativa poderíamos simplificar a fórmula para T(N) = 10*N² sem perder muita coisa.
Vamos começar pelo O-grande, que é uma maneira de dar um limite superior para o tempo gasto por um algoritmo. O(g) descreve a classe de funções que crescem no máximo tão rápido quanto a função g e quando falamos que f ∈ O(g) queremos dizer que g cresce pelo menos tão rápido quanto f. (isso é, claro, um “abuso” matemático. Lembre-se sempre que é uma classe de funções, representando um conjunto de funções)
Formalmente:
Dadas duas funções f e g, dizemos que f ∈ O(g) se existem constantes x0 e c tal que para todo x > x0 vale f(x) < c*g(x)
Nessa definição, a constante c nos dá margem para ignorar fatores constantes (o que nos permite dizer que 10*N é O(N)) e a constante x0 diz que só nos importamos para o comportamento de f e g quando o N for grande e os termos que crescem mais rápido dominem o valor total.
Para um exemplo concreto, considere aquela função de tempo f(n) = 10*N2 + 137*N + 15 de antes.
Podemos dizer que o crescimento dela é quadrático:
Podemos dizer que
f ∈ O(N²), já que parac = 11eN > 137vale
10*N² + 137*N + 15 < c * N2
Podemos escolher outros valores para c e x0, como por exemplo c = 1000 e N > 1000 (que deixam a conta bem óbvia). O valor exato desses pares não importa, o que importa é poder se convencer de que pelo menos um deles exista.
Na direção oposta do O-grande temos o Ω-grande, que é para limites inferiores. Quando falamos que f é Ω(g), estamos dizendo que f cresce pelo menos tão rápido quanto g. No nosso exemplo recorrente, também podemos dizer que f(n) cresce tão rápido quanto uma função quadrática:
Podemos dizer que
f é Ω(N²), já que parac = 1 e N > 0vale
10*N² + 137*N + 15 > c*N2
Finalmente, o Θ-grande tem a ver com aproximações justas, quando o f e o g crescem no mesmo ritmo (exceto por um possível fator constante). A diferença do Θ-grande para o O-grande e o Ω-grande é que estes admitem aproximações folgadas, (por exemplo, N² ∈ O(N³)) em que uma das funções cresce muito mais rápida que a outra.
Dentre essas três notações, a mais comum de se ver é a do O-grande. Normalmente as análises de complexidade se preocupam apenas com o tempo de execução no pior caso então o limite superior dado pelo O-grande é suficiente.
Para algoritmos recursivos usa-se normalmente uma equação de recorrência[10] para se chegar á função de custo. Então, resolve-se essa equação de recorrência para se chegar à fórmula fechada da recorrência.
Muitas vezes é muito difícil se chegar a uma fórmula fechada, então usa-se outros métodos, como a árvore de recursão e o teorema-mestre[11] para se chegar à análise assintótica (usando a notação O-grande).

Notas de rodapé:
[1] Complexidade de tempo – Wikipédia, a enciclopédia livre
[2] Análise de Algoritmos
[3] Big O notation – Wikipedia
[4] Limit superior and limit inferior – Wikipedia
[5] Asymptotic notation
[6] Time complexity – Wikipedia
[7] Notação Big-θ (Grande-Theta)
[8] Grande-O – Wikipédia, a enciclopédia livre
[9] Notação Big-Ω (Grande-Omega)
[10] http://jeffe.cs.illinois.edu/teaching/algorithms/notes/99-recurrences.pdf
[11] Teorema mestre (análise de algoritmos) – Wikipédia, a enciclopédia livre
Essa foi a minha resposta no Quora à pergunta: “Como calcular o custo de um algoritmo”.
Link: https://pt.quora.com/Como-calcular-o-custo-de-um-algoritmo
quinta-feira, 23 julho, 2020 at 12:40 pm Deixe um comentário
E a Probabilidade e a Estatística, hein?
Na faculdade eu sempre olhei muito enviesado para a Probabilidade e a Estatística, mas isso devia-se, claro, à ignorância em relação ao pensamento estatístico. Como Leonard Mlodinow nos ensina no excelente “O Andar do Bêbado: como o acaso determina nossas vidas“, e eu cito: “a mente humana foi construída para identificar uma causa definida para cada acontecimento, podendo assim ter bastante dificuldade em aceitar a influência de fatores aleatórios ou não relacionados”. É isso! Temos extrema dificuldade em entender o pensamento aleatório, probabilístico e, por consequência, o estatístico. Mas, como escrito no mesmo livro (citando o economista Armen Alchian), “os processos aleatórios são fundamentais na natureza, e onipresentes em nossa vida cotidiana; e ainda assim, a maioria das pessoas, não os compreende”.

Mas, é óbvio que isso precisa mudar. Nós, Cientistas da Computação e amantes da tecnologia e da Tecnologia da Informação em geral, não somos “a maioria das pessoas”. Precisamos mudar a nossa lógica determinística, afinal, a ciência inteira (e a Computação não fica de fora) é dominada inteiramente pela Estatística e pelo pensamento estocástico.
“O desenho de nossas vidas, como a chama da vela, é continuamente conduzido em novas direções por diversos eventos aleatórios que, juntamente com nossas reações a eles, determinam nosso destino. Como resultado, a vida é ao mesmo tempo difícil de prever e difícil de interpretar” – Leonard Mlodinow em “O Andar do Bêbado: como o acaso determina nossas vidas”
Portanto, começamos esse estudo, muitas vezes com resultados contra-intuitivos. Mas temos uma ferramenta de grande valia: o computador e as linguagens de programação. Portanto, vamos começar com um experimento básico: a probabilidade da moeda lançada.
Para isso, fiz um script em Python (2.7.11) para simular o lançamento de uma moeda e, em seguida, computar as probabilidades dos lançamentos. Os resultados são interessantes. Quanto mais o número de lançamentos aumenta mais as frequências aproximam-se do número previsto (50% para cada uma das faces).
Aqui está o código:
# -*- coding: UTF-8 -*-
"""
Função:
Exemplo de lançamento de moeda
Autor:
Professor Ed - Data: 29/05/2016 -
Observações: ?
"""
def gera_matriz_lancamentos(matriz, tamanho):
import random
matriz_faces = []
print 'Gerando...'
for x in range(tamanho):
num = random.randint(1,2) #1 = cara, 2 = coroa
matriz.append (num)
if num==1:
matriz_faces.append('Cara')
else:
matriz_faces.append('Coroa')
print matriz_faces
def calcula_probabilidades(matriz, tamanho):
soma_cara = 0
soma_coroa = 0
for i in range(len(matriz)):
if matriz[i]==1:
soma_cara = soma_cara+1
elif matriz[i]==2:
soma_coroa = soma_coroa + 1
probabilidade_cara = float(soma_cara)/float(tamanho)*100
probabilidade_coroa = float(soma_coroa)/float(tamanho)*100
print 'Foram lancadas ' + str(soma_cara) + ' caras e ' + str(soma_coroa) + ' coroas'
probabilidades = []
probabilidades.append(probabilidade_cara)
probabilidades.append(probabilidade_coroa)
return probabilidades
matriz=[]
tamanho = int(raw_input('Digite o tamanho da matriz de lancamentos: '))
gera_matriz_lancamentos(matriz, tamanho)
#print 'Um para cara e 2 para coroa'
#print matriz
vetor_probabilidades = []
vetor_probabilidades = calcula_probabilidades(matriz, tamanho)
print 'As probabilidades sao: %f%% e %f%%' % (vetor_probabilidades[0], vetor_probabilidades[1])
Nem sempre, como os números gerados pelo computador são (pseudo)aleatórios (falaremos disto depois), as frequências são próximas a 50% (variando bastante entre as execuções do programa), mas, em geral, sempre que a quantidade de lançamentos é imensa (acima de 10.000), as probabilidades aproximam-se do limite esperado.
Lembrando, sempre, que se lançarmos uma moeda um milhão de vezes não deveríamos esperar um placar exato (50% caras e 50% coroas). A teoria das probabilidades nos fornece uma medida do tamanho da diferença (chamada de erro) que pode existir neste experimento de um processo aleatório. Se ma moeda for lançada, digamos, N vezes, haverá um distanciamento (erro) de aproximadamente 1/2 N “caras”, este erro, de fato, pode ser para um lado ou para o outro. Ou seja, espera-se que, em “moedas honestas“, o erro seja da ordem da raiz quadrada de N.
Assim, digamos que de cada 1.000.000 lançamentos de uma moeda honesta, o número de caras se encontrará, provavelmente entre 499.000 e 501.000 (já que 1.000 é a raiz quadrada de N). Para moedas viciadas, espera-se que o erro seja consistentemente maior que a raiz quadrada de N.
 Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Abaixo, um exemplo de uma instância com 100.000 lançamentos provando que as frequências, de fato, aproximam-se das probabilidades previstas (inclusive se considerado o erro):

Segundo a Lei dos Grandes Números, a média aritmética dos resultados da realização da mesma experiência repetidas vezes tende a se aproximar do valor esperado à medida que mais tentativas se sucederem. E, claro, se todos os eventos tiverem igual probabilidade o valor esperado é a média aritmética. (Lembrando, claro, que o valor em si, não pode ser “esperado” no sentido geral, o que leva à uma falácia). Ou seja, quanto mais tentativas são realizadas, mais a probabilidade da média aritmética dos resultados observados se aproximam da probabilidade real.
A Probabilidade é descrita por todos, alunos, professores e estudantes, como difícil. Em minha opinião, ela dá a impressão de ser difícil porque muitas vezes, desafia nosso senso comum (que, normalmente, tende sempre à falácia do apostador, ou de Monte Carlo), ainda mais quando dispomos do conhecimento da lei dos grandes números. Estratégias como “o dobro ou nada” nadam de braçadas no inconsciente coletivo com esta falácia.
O teorema de Bayes (que é um corolário da Lei da Probabilidade Total) explica direitinho o porque da falácia do apostador ser, bem, …, uma falácia. Sendo a moeda honesta, os resultados em diferentes lançamentos são estatisticamente independentes e a probabilidade de ter cara em um único lançamento é exatamente 1⁄2.
É isso aí. Nos próximos posts vamos falar um pouco mais sobre os significados e como calcular essas probabilidades, sempre tentando um enfoque prático com a ajuda dessa ferramenta magnífica que é o computador!
Até!
P.S.: Assim que meu repositório for clonado certinho (tive uns problemas com o Git local) eu coloco o link para o programa prontinho no Github.
Pronto! Já apanhei resolvi o problema do Git e você pode baixar o arquivo-fonte clicando aqui.
P.S.1: Acabei não resistindo e fazendo o teste para 1.000.000 de lançamentos. O resultado está aqui embaixo. Confira:

Aula 02 de Estrutura de Dados e questões sobre a primalidade de inteiros
Já está disponível a AULA 02 de Estrutura de Dados. Para baixar, basta clicar aqui.
Lembrando que retirei o slide que continha o programa com o teste de primalidade, já que ele deverá ser enviado como trabalho até dia 26/04, quinta-feira. Após este período colocarei a aula completa, lembrando que como comentei este teste de primalidade é extremamente ineficiente.
Sobre a questão de primalidade de números inteiros, recomendadíssimo a leitura sobre o teste de primalidade AKS, conhecido como teste da primalidade Agrawal-Kayal-Saxena. E também o teste de primalidade de Fermat para geração de números não-primos ou mesmo o teste de primalidade de Miller-Rabin (que é probabilístico).
Para entender de verdade os (fascinantes) números primos, recomendo, para quem está com tempo, a leitura deste trabalho.
Um abs.
Depois volto aqui e posto sobre os números primos com questões relacionadas aos algoritmos para obtê-los e toda a mística que os envolvem.
Até mais.
(P.S. – Um pequeno desafio a meus alunos – bem fácil, diga-se – é implementar em C o algoritmo do teste de primalidade AKS e me enviar!)
A Matemática de tudo
Quando disse para um amigo meu do trabalho que iria fazer uma apresentação sobre Matemática para alunos do ensino médio ele (não sei porque) ficou intrigado. “Como pode uma apresentação de Matemática”, ele retrucou. Fiquei a madrugada preparando o material que iria fazer parte da Semana de Matemática da Escola KJK (Kairala José Kairala que, por acaso, foi onde cursei o ensino médio!). Comecei por volta das 11 horas e, felizmente, 45 minutos depois, às 11:45 TODOS os alunos e alunas ainda estavam no auditório quente (sem ar condicionado naquele dia) viajando com os devaneios e maravilhas da Matemática
Compartilho agora esta apresentação que fiz para pouco mais de 200 alunos do ensino médio do KJK na semana de #matemática de 2010: Chama-se “A matemática de tudo”.
Fui à escola à pedido do professor de filosofia Edmilson Lima que, por acaso, é meu pai (e hoje, 30/05, comemora meio século de vida \o/). A apresentação mostra o quanto estamos rodeados de matemática por todos os lados e demonstra que sem ela jamais estaríamos no atual estado tecnológico e científico que nos encontramos…
Link: http://www.slideshare.net/edkallenn/a-matemtica-de-tudo-edkallenn-lima ou então clique aqui.
“A matemática é o alfabeto pelo qual Deus criou o universo” – Galileu Galilei.
P.S. Uma pena os vídeos não puderem ser compartilhadas, mas prometo que os posto no Youtube e depois volto aqui e atualizo este post com os links. Abs.
O porquê da matemática!
Muitos, muitíssimos alunos dos cursos de Informática e de Tecnologia da Informação reclamam do excesso de matemática e do porquê de tanto formalismo num curso em que a ferramenta de trabalho é o computador (Meus antigos alunos viviam reclamando!). Deixando de lado a contradição latente de tal pergunta (visto que a TI é muita mais da área das Exatas que das Humanas) mostro aqui embaixo em exemplo extraído do FAQ sobre carreiras (e emprego) da Blizzard. Para os gamers esse nome dispensa apresentações, mas para quem não conhece, a Blizzard é a empresa responsável por megasucessos dos games, entre os quais destaco: World of Warcraft, Diablo III, Starcraft, Diablo II (que à época de seu lançamento, pelos idos de 2000, demoliu minha vida social), Warcraft III. Além do magnífico Rock n’ Roll Racing.
A Blizzard é famosa por seus jogos de qualidade impecável, vício latente e bastante esmero na programação dos mesmos. Pois bem, esta empresa está precisando contratar gente. Em seu website ela mostra as carreiras disponíveis. Há também um FAQ sobre carreiras. Neste FAQ, me interessou a seguinte pergunta/resposta (o grifo é totalmente meu):
O que preciso saber para ser programador da Blizzard?
A Blizzard tem várias vagas de programação. Precisamos de programadores para trabalhar na Battle.net, em jogos, em gráficos e 3D, ferramentas e outras áreas. Todas as vagas requerem conhecimentos profundos de C e C++. Quem tem um alicerce sólido nessa área pode adquirir outras habilidades. Conhecimentos de probabilidade, estatística, geometria e outras ciências matemáticas são úteis. Consulte a seção de empregos do nosso website para conhecer mais detalhes sobre as vagas de programação.
Preciso falar mais alguma coisa?
Se não acredita, é só conferir: http://us.blizzard.com/pt-br/company/careers/faq.html
C e C++ continuam vivíssimos (aqui respondo um velho questionamento de um aluno sobre porque aprender C/C++ hoje em dia). E o que está sublinhado parece ser a velha e boa ciência de Euclides e Arquimedes. Aquela que espanta os neófitos e abre um sorrisão no rosto dos que compreendem os mistérios por detrás daqueles símbolos.
Computação gráfica, algoritmos avançados e modelagem 3D ainda fazem bastante uso da rainha das ciências e este, além do conhecimento per se, é o maior motivo para se aprender “o alfabeto pelo qual Deus criou o universo” – (Galileu).
Até que trabalhar num lugar assim também não parece mau negócio:




Para mais fotos, ou informações é só conferir lá no site oficial da Blizzard (em português!)
Sistema de Busca apaixonante… (Wolfram Alfa)
Eu conheci hoje um sistema de busca viciante e apaixonante (sim, mais do que o Google) chamado Wolfram Alfa. Para mim, que era fãzaço do programa Mathematica, então, nem se fala. O negócio é o seguinte: o Wolfram é visto com mais um google killer, embora, depois de usar bastante o serviço eu concorde com o Tiago Dória de que eles são mais complementares do que rivais, pois a proposta é (bem) diferente.
Entre outras cositas bacanas, com o Wolfram você faz cálculos (de uma complexidade viciante), e responde a perguntas e queries objetivamente e com dados (muuuitos dados). Por exemplo, experimentei a seguinte query no sistema de busca do sistema: “R$ 5400 in dollars”. A resposta: confiram que lindeza de resposta e digam se o negócio não é apaixonante.
O lance do sistema é respostas exatas sem links para páginas onde vc encontraria o conhecimento por si só. Ele me dá a localização exta da estação espacial internacional, o desenvolvimento da série de Taylor para sen^2(x), me mostra a diferença em nível físico-químico entre a cafeína e a aspirina, interpreta notas musicais mostrando as distâncias de tons e semitons entre elas (bom, por exemplo, para transpor os tons de escalas e cifras musicais), desenvolve, por exemplo a integral indefinida de uma função, como, por exemplo: 
, mostra os terremotos próximos à ponte Akashi-Kaikyō no japão, mostra o clima em Boston em 1998 (e mesmo o de Rio Branco em 2002), um gráfico de crescimento das meninas nascidas em 29 de junho de 2000, informações sobre um icosaedro, dados sobre a cidade que estou morando atualmente e uma INFINADE de outras informações.
O serviço ainda está em testes e as perguntas são sempre em Inglês, mas que as possibilidades (de crescimento e de pesquisas) são fascinantes, isso são. Ah, como bem lebra o Tiago Dória, é sempre bom confrontar os dados oriundos da Internet com outras fontes, sejam elas reais ou virtuais.
Até.

Algoritmo de Euclides
O algoritmo de Euclides para obtenção do MDC pode ser descrito como uma série de divisões sucessivas, o que dispensa fatoração.
Continue Reading sexta-feira, 15 maio, 2009 at 4:16 pm 2 comentários
Dia nacional da Matemática
Bom, ao menos uma coisa vossas excelências, os nossos parlamentares sabem fazer bem: criar feriados e datas comemorativas.
Pois bem, hoje comemora-se (sem muito alarde, é verdade!) o DIA NACIONAL DA MATEMÁTICA. Hoje, dia do nascimento do grande carioca Julio César de Mello e Souza, mais conhecido como Malba Tahan. Sim, ele mesmo, autor de “O Homem que calculava”, brasileiríssimo como eu (embora menos miscigenado que eu, eu creio! rsrs).
Malba Tahan era um divulgador da matemática além de amante e professor da arte de Arquimedes, Leibiniz, Diofanto, Euclides, Newton , Bhaskara, Euler, Gauss, Fermat e muitos, muitos outros cérebros que contribuíram para a construção de nossa sociedade, de nossa ciência e de tudo o que nos possibilita a sociedade atual ser do jeito que ela é.
Malba Tahan foi mais do que um amante da Matemática. Ele imaginava que essa bela ciência era bem melhor ensinada e aprendida se fosse (oh! Horror dos horrores dos maus professores), vejam só, DIVERTIDA.
Ainda há muitos que acreditam nessa possibilidade. Para todos os mestres que fazem da arte de Pitágoras um divertido aprendizado e para o grande Malba Tahan, os mais sincerosos e honrosos parabéns.


Comentários