Posts tagged ‘Estruturas de Dados’
Pseudocódigo. Outra forma de representar algoritmos
Nós já vimos duas das principais formas de representar algoritmos, a descrição narrativa e os fluxogramas. Hoje vamos ver a terceira.
A representação e descrição de algoritmos é uma parte fundamental da programação. Ela permite que os desenvolvedores comuniquem de forma clara e concisa a lógica e os passos necessários para resolver um problema ou realizar uma tarefa. O pseudocódigo é uma forma de representação de algoritmos que combina elementos de linguagem de programação com linguagem natural, tornando-o mais compreensível para humanos, independentemente da linguagem de programação específica.
O pseudocódigo não é uma linguagem de programação real, mas sim uma maneira de descrever a sequência de passos lógicos de um algoritmo. Ele utiliza convenções e estruturas de controle semelhantes às linguagens de programação, como declarações condicionais, loops e instruções de atribuição, permitindo que o desenvolvedor descreva a lógica de um algoritmo de maneira clara e estruturada.
Vamos considerar um exemplo simples para ilustrar o uso do pseudocódigo. Suponha que queremos escrever um algoritmo para calcular a média aritmética de três números. Utilizando pseudocódigo, poderíamos representar o algoritmo da seguinte forma:
1. Ler três números (num1, num2, num3)
2. Calcular a soma dos três números (soma = num1 + num2 + num3)
3. Calcular a média (media = soma / 3)
4. Exibir a médiaNesse exemplo, cada linha descreve uma etapa do algoritmo. Na linha 1, estamos lendo os três números, e na linha 2, calculamos a soma dos três números. Em seguida, na linha 3, calculamos a média dividindo a soma pelo número de elementos (3). Por fim, na linha 4, exibimos o resultado da média.
O pseudocódigo permite que o desenvolvedor se concentre na lógica do algoritmo, independentemente da sintaxe de uma linguagem de programação específica. Isso facilita a compreensão e a comunicação do algoritmo entre os membros da equipe de desenvolvimento.
Além disso, o pseudocódigo é altamente flexível e pode ser adaptado de acordo com as necessidades do projeto. Por exemplo, se desejarmos adicionar uma verificação de erro para garantir que os números inseridos sejam válidos, poderíamos modificar o pseudocódigo da seguinte maneira:
1. Ler três números (num1, num2, num3)
2. Verificar se os números são válidos
2.1. Se algum número for inválido, exibir uma mensagem de erro e encerrar o programa
3. Calcular a soma dos três números (soma = num1 + num2 + num3)
4. Calcular a média (media = soma / 3)
5. Exibir a médiaNesse caso, adicionamos uma etapa extra (2) para verificar se os números são válidos. Se algum número for inválido, exibimos uma mensagem de erro e encerramos o programa. Essa modificação pode ser facilmente realizada no pseudocódigo, sem se preocupar com a sintaxe de uma linguagem de programação específica.
O uso de pseudocódigo também é comum em documentação técnica e algoritmos complexos, onde a compreensão do fluxo lógico é essencial. Ele pode ser facilmente convertido em código real em uma linguagem de programação específica, pois o pseudocódigo é projetado para ser independente de uma linguagem em particular.

Basicamente, o pseudocódigo é uma forma eficaz de representar e descrever algoritmos. Ele combina elementos de linguagem de programação com linguagem natural, permitindo que os desenvolvedores expressem a lógica do algoritmo de forma clara e estruturada. O pseudocódigo facilita a comunicação, a compreensão e a implementação dos algoritmos, independentemente da linguagem de programação utilizada.
Portugol
A representação e descrição de algoritmos utilizando o pseudocódigo conhecido como Portugol é uma prática amplamente utilizada no ensino e aprendizado de programação. O Portugol é uma linguagem de programação simplificada que permite aos iniciantes compreenderem a lógica e a estrutura dos algoritmos de forma mais clara e intuitiva, sem se preocuparem com a sintaxe complexa de linguagens de programação reais.
Ao utilizar o Portugol para representar algoritmos, é possível descrever passos sequenciais, estruturas condicionais e repetições de forma fácil e compreensível. Vamos considerar um exemplo simples de cálculo de média aritmética utilizando o Portugol:
Algoritmo "CalculaMedia"
Var
num1, num2, num3, soma, media: Real
Início
Escreva("Digite o primeiro número: ")
Leia(num1)
Escreva("Digite o segundo número: ")
Leia(num2)
Escreva("Digite o terceiro número: ")
Leia(num3)
soma <- num1 + num2 + num3
media <- soma / 3
Escreva("A média é: ", media)
Fim
Neste exemplo, utilizamos o pseudocódigo Portugol para representar um algoritmo que lê três números, calcula a soma e a média aritmética dos mesmos, e exibe o resultado. As palavras-chave “Algoritmo”, “Var”, “Início” e “Fim” são utilizadas para definir a estrutura básica do algoritmo em Portugol.
Dentro da estrutura do algoritmo, utilizamos comandos como “Escreva” para exibir mensagens na tela, “Leia” para receber valores digitados pelo usuário, e os operadores matemáticos para realizar os cálculos necessários.
O uso do pseudocódigo Portugol é especialmente útil para iniciantes na programação, pois permite que eles se concentrem na lógica e na sequência de passos necessários para resolver um problema, sem se preocuparem com os detalhes específicos de uma linguagem de programação real. Dessa forma, os iniciantes podem aprender a estrutura básica dos algoritmos e ganhar confiança antes de se aventurarem em linguagens de programação mais complexas.
É importante ressaltar que o Portugol é apenas uma representação simplificada e não é executável diretamente. Ele serve como um meio de compreensão e aprendizado dos conceitos fundamentais da programação. Uma vez que o algoritmo tenha sido representado em Portugol, é possível traduzi-lo para uma linguagem de programação real, como Java, Python ou C, para que possa ser compilado e executado.
Como exemplo de pseudocódigos (em formas de programas) temos o Visualg (que usa uma versão do Portugol mais parecida com a usada no texto) e o Portugol Studio.
Até a próxima.
segunda-feira, 13 novembro, 2023 at 4:10 pm Deixe um comentário
Recursividade: a multiplicação recursiva, as definições matemáticas por indução/recursão e os axiomas de Peano
A recursividade, como já vimos anteriormente deve primeiro sempre ser pensada nos casos mais simples (os casos bases ou casos básicos). Vamos ver um exemplo para nos ajudar.
É possível, por exemplo, definir a multiplicação de dois números inteiros m e n, sendo n > 0, em termos da operação de adição. O caso mais simples dessa operação é aquele no qual n = 0. Nesse caso, o resultado da operação é igual a 0, independentemente do valor de m. De acordo com a idéia exposta acima, precisamos agora pensar em como podemos expressar a solução desse problema no caso em que n > 0, supondo que sabemos determinar sua solução para casos mais simples, que se aproximam do caso básico. Neste caso, podemos expressar o resultado de m × n em termos do resultado da operação, mais simples m × (n − 1); ou seja, podemos definir m × n como sendo igual a m + (m × (n − 1)),
para n > 0. Ou seja, a operação de multiplicação pode então ser definida indutivamente pelas seguintes equações:
,
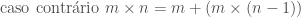
Uma maneira alternativa de pensar na solução desse problema seria pensar na operação de multiplicação m * n como a repetição, n vezes, da operação de adicionar m, isto é:
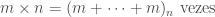
Raciocínio análogo pode ser usado para expressar a operação de exponenciação, com expoente inteiro não-negativo, em termos da operação de multiplicação (que será visto em outro post).

O programa a seguir apresenta, na linguagem C, uma forma computar o resultado da multiplicação de dois números, dados como argumentos dessas operações de forma recursiva. As função multiplica é definida usando-se chamadas à própria função, razão pela qual ela é chamada de recursiva.
int multiplica(int num1, int num2){
//multiplicação por zero
if (num1 == 0 || num2 == 0) {
return 0;
}
//caso base, onde a recursão para:
else if (num2 == 1) {
return num1;
}
//multiplicando através da soma com recursividade:
else {
return (num1 + multiplica(num1,num2 - 1));
}
}
Considere a função multiplica definida acima. A sua definição espelha diretamente a definição recursiva da operação de multiplicação, em termos da adição, apresentada anteriormente. Ou seja, multiplicar m por n (onde n é um inteiro não-negativo) fornece:
-
0, no caso base (isto é, sen==0); m + multiplica(m, n-1), no caso indutivo/recursivo (isto é,se n!=0).
Vejamos agora, mais detalhadamente, a execução de uma chamada multiplica(3,2). Cada chamada da função multiplica cria novas variáveis, de nome m e n. Existem, portanto, várias variáveis com nomes (m e n), devido às chamadas recursivas. Nesse caso, o uso do nome refere-se à variável local ao corpo da função que está sendo executado. As execuções das chamadas de funções são feitas, dessa forma, em uma estrutura de pilha. Chamamos, genericamente, de estrutura de pilha uma estrutura na qual a inserção (ou alocação) e a retirada (ou liberação) de elementos é feita de maneira que o último elemento inserido é o primeiro a ser retirado.
Em resumo, na tabela abaixo, representamos a estrutura de pilha criada pelas chamadas à função multiplica. Os nomes m e n referem-se, durante a execução, às variáveis mais ao topo dessa estrutura. Uma chamada recursiva que vai começar a ser executada está indicada por um negrito. Nesse caso, o resultado da expressão, ainda não conhecido, é indicado por “…”.
Tabela 4.2: Passos na execução de multiplica(3,2) |
| Comando/Expressão | Resultado (expressão) | Estado (após execução/avaliação) |
multiplica(3,2) … | m↦ 3n↦ 2 | |
n == 0 | falso | m↦ 3n↦ 2 |
return m + multiplica(m,n-1) | … | m↦ 3 m↦ 3n↦ 2 n↦ 1 |
n == 0 | falso | m↦ 3 m↦ 3n↦ 2 n↦ 1 |
return m + multiplica(m,n-1) | … | m↦ 3 m↦ 3 m↦ 3n↦ 2 n↦ 1 n↦ 0 |
n == 0 | verdadeiro | m↦ 3 m↦ 3 m↦ 3n↦ 2 n↦ 1 n↦ 0 |
return 0 | m↦ 3 m↦ 3n↦ 2 n↦ 1 | |
return m + 0 | m↦ 3n↦ 2 | |
return m + 3 | ||
multiplica(3,2) | 6 |
E assim vemos como o procedimento recursivo para multiplicar dois números funciona com um exemplo em linguagem C, facilmente portável para outra linguagem.
Agora, para uma visão matematicamente mais precisa, continue lendo…
Definições por indução
As definições por indução (usando o princípio da indução dos axiomas de Peano) se baseiam na possibilidade de se iterar uma função 
n, de vezes.
Mais precisamente, seja 


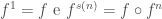


s(n) é o sucessor de um número natural n, conforme descrito nos axiomas de Peano).
Numa exposição mais, digamos, sistemática da teoria dos números naturais, a existência da n-ésima iterada 

É importante ressaltar que não é possível, nesta altura, definir 
n é, por enquanto, apenas um elemento do conjunto 
Admitamos assim que, dada uma função 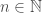
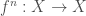
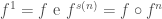
Agora, podemos ver um exemplo de definição por indução (recursão) usando o que acabamos de ver, as iteradas da função 
O produto, a multiplicação, de dois números naturais é definido da seguinte forma:
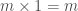

Em outras palavras: multiplicar um número 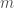


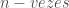
Assim, por exemplo, 
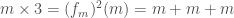
Lembrando a definição de 

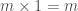

Que é exatamente a mesma definição recursiva que vimos acima!
E a Probabilidade e a Estatística, hein?
Na faculdade eu sempre olhei muito enviesado para a Probabilidade e a Estatística, mas isso devia-se, claro, à ignorância em relação ao pensamento estatístico. Como Leonard Mlodinow nos ensina no excelente “O Andar do Bêbado: como o acaso determina nossas vidas“, e eu cito: “a mente humana foi construída para identificar uma causa definida para cada acontecimento, podendo assim ter bastante dificuldade em aceitar a influência de fatores aleatórios ou não relacionados”. É isso! Temos extrema dificuldade em entender o pensamento aleatório, probabilístico e, por consequência, o estatístico. Mas, como escrito no mesmo livro (citando o economista Armen Alchian), “os processos aleatórios são fundamentais na natureza, e onipresentes em nossa vida cotidiana; e ainda assim, a maioria das pessoas, não os compreende”.

Mas, é óbvio que isso precisa mudar. Nós, Cientistas da Computação e amantes da tecnologia e da Tecnologia da Informação em geral, não somos “a maioria das pessoas”. Precisamos mudar a nossa lógica determinística, afinal, a ciência inteira (e a Computação não fica de fora) é dominada inteiramente pela Estatística e pelo pensamento estocástico.
“O desenho de nossas vidas, como a chama da vela, é continuamente conduzido em novas direções por diversos eventos aleatórios que, juntamente com nossas reações a eles, determinam nosso destino. Como resultado, a vida é ao mesmo tempo difícil de prever e difícil de interpretar” – Leonard Mlodinow em “O Andar do Bêbado: como o acaso determina nossas vidas”
Portanto, começamos esse estudo, muitas vezes com resultados contra-intuitivos. Mas temos uma ferramenta de grande valia: o computador e as linguagens de programação. Portanto, vamos começar com um experimento básico: a probabilidade da moeda lançada.
Para isso, fiz um script em Python (2.7.11) para simular o lançamento de uma moeda e, em seguida, computar as probabilidades dos lançamentos. Os resultados são interessantes. Quanto mais o número de lançamentos aumenta mais as frequências aproximam-se do número previsto (50% para cada uma das faces).
Aqui está o código:
# -*- coding: UTF-8 -*-
"""
Função:
Exemplo de lançamento de moeda
Autor:
Professor Ed - Data: 29/05/2016 -
Observações: ?
"""
def gera_matriz_lancamentos(matriz, tamanho):
import random
matriz_faces = []
print 'Gerando...'
for x in range(tamanho):
num = random.randint(1,2) #1 = cara, 2 = coroa
matriz.append (num)
if num==1:
matriz_faces.append('Cara')
else:
matriz_faces.append('Coroa')
print matriz_faces
def calcula_probabilidades(matriz, tamanho):
soma_cara = 0
soma_coroa = 0
for i in range(len(matriz)):
if matriz[i]==1:
soma_cara = soma_cara+1
elif matriz[i]==2:
soma_coroa = soma_coroa + 1
probabilidade_cara = float(soma_cara)/float(tamanho)*100
probabilidade_coroa = float(soma_coroa)/float(tamanho)*100
print 'Foram lancadas ' + str(soma_cara) + ' caras e ' + str(soma_coroa) + ' coroas'
probabilidades = []
probabilidades.append(probabilidade_cara)
probabilidades.append(probabilidade_coroa)
return probabilidades
matriz=[]
tamanho = int(raw_input('Digite o tamanho da matriz de lancamentos: '))
gera_matriz_lancamentos(matriz, tamanho)
#print 'Um para cara e 2 para coroa'
#print matriz
vetor_probabilidades = []
vetor_probabilidades = calcula_probabilidades(matriz, tamanho)
print 'As probabilidades sao: %f%% e %f%%' % (vetor_probabilidades[0], vetor_probabilidades[1])
Nem sempre, como os números gerados pelo computador são (pseudo)aleatórios (falaremos disto depois), as frequências são próximas a 50% (variando bastante entre as execuções do programa), mas, em geral, sempre que a quantidade de lançamentos é imensa (acima de 10.000), as probabilidades aproximam-se do limite esperado.
Lembrando, sempre, que se lançarmos uma moeda um milhão de vezes não deveríamos esperar um placar exato (50% caras e 50% coroas). A teoria das probabilidades nos fornece uma medida do tamanho da diferença (chamada de erro) que pode existir neste experimento de um processo aleatório. Se ma moeda for lançada, digamos, N vezes, haverá um distanciamento (erro) de aproximadamente 1/2 N “caras”, este erro, de fato, pode ser para um lado ou para o outro. Ou seja, espera-se que, em “moedas honestas“, o erro seja da ordem da raiz quadrada de N.
Assim, digamos que de cada 1.000.000 lançamentos de uma moeda honesta, o número de caras se encontrará, provavelmente entre 499.000 e 501.000 (já que 1.000 é a raiz quadrada de N). Para moedas viciadas, espera-se que o erro seja consistentemente maior que a raiz quadrada de N.
 Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Abaixo, um exemplo de uma instância com 100.000 lançamentos provando que as frequências, de fato, aproximam-se das probabilidades previstas (inclusive se considerado o erro):

Segundo a Lei dos Grandes Números, a média aritmética dos resultados da realização da mesma experiência repetidas vezes tende a se aproximar do valor esperado à medida que mais tentativas se sucederem. E, claro, se todos os eventos tiverem igual probabilidade o valor esperado é a média aritmética. (Lembrando, claro, que o valor em si, não pode ser “esperado” no sentido geral, o que leva à uma falácia). Ou seja, quanto mais tentativas são realizadas, mais a probabilidade da média aritmética dos resultados observados se aproximam da probabilidade real.
A Probabilidade é descrita por todos, alunos, professores e estudantes, como difícil. Em minha opinião, ela dá a impressão de ser difícil porque muitas vezes, desafia nosso senso comum (que, normalmente, tende sempre à falácia do apostador, ou de Monte Carlo), ainda mais quando dispomos do conhecimento da lei dos grandes números. Estratégias como “o dobro ou nada” nadam de braçadas no inconsciente coletivo com esta falácia.
O teorema de Bayes (que é um corolário da Lei da Probabilidade Total) explica direitinho o porque da falácia do apostador ser, bem, …, uma falácia. Sendo a moeda honesta, os resultados em diferentes lançamentos são estatisticamente independentes e a probabilidade de ter cara em um único lançamento é exatamente 1⁄2.
É isso aí. Nos próximos posts vamos falar um pouco mais sobre os significados e como calcular essas probabilidades, sempre tentando um enfoque prático com a ajuda dessa ferramenta magnífica que é o computador!
Até!
P.S.: Assim que meu repositório for clonado certinho (tive uns problemas com o Git local) eu coloco o link para o programa prontinho no Github.
Pronto! Já apanhei resolvi o problema do Git e você pode baixar o arquivo-fonte clicando aqui.
P.S.1: Acabei não resistindo e fazendo o teste para 1.000.000 de lançamentos. O resultado está aqui embaixo. Confira:

Aulas de Estruturas de Dados (03, 04, 05 e 06)
Aqui estão disponíveis as aulas 03, 04, 05 e 06 de Estruturas de Dados e seus respectivos exercícios (inseridos nas próprias aulas). As datas de entrega dos exercícios foram comentadas somente em sala de aula. Curtam e estudem. (Lembrando que o material de Estruturas de Dados em C está reduzido pelo pouco tempo disponível devido a troca de professores). Para baixar é só clicar:
Estruturas de Dados – Aula 03
Estruturas de Dados – Aula 04
Estruturas de Dados – Aula 05
Estruturas de Dados – Aula 06
Bons estudos!
Aula 02 de Estrutura de Dados e questões sobre a primalidade de inteiros
Já está disponível a AULA 02 de Estrutura de Dados. Para baixar, basta clicar aqui.
Lembrando que retirei o slide que continha o programa com o teste de primalidade, já que ele deverá ser enviado como trabalho até dia 26/04, quinta-feira. Após este período colocarei a aula completa, lembrando que como comentei este teste de primalidade é extremamente ineficiente.
Sobre a questão de primalidade de números inteiros, recomendadíssimo a leitura sobre o teste de primalidade AKS, conhecido como teste da primalidade Agrawal-Kayal-Saxena. E também o teste de primalidade de Fermat para geração de números não-primos ou mesmo o teste de primalidade de Miller-Rabin (que é probabilístico).
Para entender de verdade os (fascinantes) números primos, recomendo, para quem está com tempo, a leitura deste trabalho.
Um abs.
Depois volto aqui e posto sobre os números primos com questões relacionadas aos algoritmos para obtê-los e toda a mística que os envolvem.
Até mais.
(P.S. – Um pequeno desafio a meus alunos – bem fácil, diga-se – é implementar em C o algoritmo do teste de primalidade AKS e me enviar!)


Comentários