Posts filed under ‘Aulas’
Como calcular o custo de um algoritmo?
De forma rápida, existem duas formas de se calcular o custo de um algoritmo:
- Usando o cálculo de complexidade de tempo[1] (em que o custo é expresso por uma função que varia sobre o tamanho da entrada do algoritmo) e
- Usando o cálculo de complexidade de espaço (em que o custo é expresso por uma função que varia também sobre o espaço em memória, primária ou secundária, usado para finalizar o algoritmo).
A mais comum é calcular a complexidade de tempo ou através de uma função de custo associada ao algoritmo[2] ou à complexidade do pior caso expresso em termos da Notação Assintótica do pior caso[3] (que representa um limite superior[4] para o algoritmo).
Para se chegar à função de custo, normalmente se conta quantas instruções são executadas para o algoritmo para resolver um problema. A função de custa é expressa por um polinômio, em relação ao tamanho da entrada.
Por exemplo, no algoritmo
for(i=0; i<N; i++){
print(i);
}
poderíamos dizer que o tempo gasto é
T(N) =
N*(tempo gasto por uma comparação entre i e N) +
N*(tempo gasto para incrementar i) +
N*(tempo gasto por um print)
Isso daria, no caso, a função de custo T(N) em relação ao tamanho da entrada N.
Já a complexidade usando notação assintótica é, geralmente, mais usada para classes de algoritmos por conta da sua simplicidade e abstração. Siga o raciocínio:
Ao ver uma expressão como n+10 ou n²+1, a maioria das pessoas pensa automaticamente em valores pequenos de n. A análise de algoritmos faz exatamente o contrário: ignora os valores pequenos e concentra-se nos valores enormes de n. Para valores enormes de n, as funções n² , (3/2)n² , 9999n² , n²/1000 , n²+100n , etc. crescem todas com a mesma velocidade e portanto são todas equivalentes.
Esse tipo de matemática, interessado somente em valores enormes de n, é chamado comportamento assintótico[5]. Nessa matemática, as funções são classificadas em ordens[6] (como as ordens religiosas da Idade Média); todas as funções de uma mesma ordem são equivalentes. As cinco funções acima, por exemplo, pertencem à mesma ordem.
Essa ideia reflete que precisamos focar, na verdade, em quão rápido uma função cresce com o tamanho da entrada.(essa é a base da “análise de algoritmos” e o centro de como se calcular o custo de um algoritmo).
Nós chamamos isso de taxa de crescimento do tempo de execução. Para manter as coisas tratáveis, precisamos simplificar a função até evidenciar a parte mais importante e deixar de lado as menos importantes.
Por exemplo, suponha que um algoritmo, sendo executado com uma entrada de tamanho n, leve 6n²+100n+300 instruções de máquina. O termo 6n² torna-se maior do que os outros termos, 100n+300 uma vez que n torna-se grande o suficiente. A partir de 20 neste caso.
Abaixo temos um gráfico que mostra os valores de 6n² e 100n+300 para valores de n variando entre 0 e 100:
Podemos dizer que este algoritmo cresce a uma taxa n², deixando de fora o coeficiente 6 e os termos restantes 100n+300. Não é realmente importante que coeficientes usamos, já que o tempo de execução é an²+bn+c, para alguns números a>0, b, e c, sempre haverá um valor de n para o qual an² é maior que bn+c e essa diferença aumenta juntamente com n. Por exemplo, aqui está um gráfico mostrando os valores de 0,6n² e 1000n+3000 de modo que reduzimos o coeficiente de n² por um fator de 10 e aumentamos as outras duas constantes por um fator de 10:
O valor de n para o qual 0,6n² se torna maior que 1000n+3000 aumentou, mas sempre haverá um ponto de cruzamento, independentemente das constantes. E a partir deste valor de cruzamento, 0,6n² sempre crescerá mais rapidamente (e sempre será maior).
Descartando os termos menos significativos e os coeficientes constantes, podemos nos concentrar na parte importante do tempo de execução de um algoritmo — sua taxa de crescimento — sem sermos atrapalhados por detalhes que complicam sua compreensão. Quando descartamos os coeficientes constantes e os termos menos significativos, usamos notação assintótica. Usa-se, normalmente, três formas: notação Θ[7] , notação O[8] , notação Ω[9] .
Por exemplo, suponha que tenhamos nos esforçado bastante e descoberto que um certo algoritmo gasta tempo
T(N) = 10*N² + 137*N + 15Nesse caso o termo quadrático 10*N² é mais importante que os outros pois para praticamente qualquer valor de N ele irá dominar o total da soma. A partir de N ≥ 14 o termo quadrático já é responsável pela maioria do tempo de execução e para N > 1000 ele já é responsável por mais de 99%. Para fins de estimativa poderíamos simplificar a fórmula para T(N) = 10*N² sem perder muita coisa.
Vamos começar pelo O-grande, que é uma maneira de dar um limite superior para o tempo gasto por um algoritmo. O(g) descreve a classe de funções que crescem no máximo tão rápido quanto a função g e quando falamos que f ∈ O(g) queremos dizer que g cresce pelo menos tão rápido quanto f. (isso é, claro, um “abuso” matemático. Lembre-se sempre que é uma classe de funções, representando um conjunto de funções)
Formalmente:
Dadas duas funções f e g, dizemos que f ∈ O(g) se existem constantes x0 e c tal que para todo x > x0 vale f(x) < c*g(x)
Nessa definição, a constante c nos dá margem para ignorar fatores constantes (o que nos permite dizer que 10*N é O(N)) e a constante x0 diz que só nos importamos para o comportamento de f e g quando o N for grande e os termos que crescem mais rápido dominem o valor total.
Para um exemplo concreto, considere aquela função de tempo f(n) = 10*N2 + 137*N + 15 de antes.
Podemos dizer que o crescimento dela é quadrático:
Podemos dizer que
f ∈ O(N²), já que parac = 11eN > 137vale
10*N² + 137*N + 15 < c * N2
Podemos escolher outros valores para c e x0, como por exemplo c = 1000 e N > 1000 (que deixam a conta bem óbvia). O valor exato desses pares não importa, o que importa é poder se convencer de que pelo menos um deles exista.
Na direção oposta do O-grande temos o Ω-grande, que é para limites inferiores. Quando falamos que f é Ω(g), estamos dizendo que f cresce pelo menos tão rápido quanto g. No nosso exemplo recorrente, também podemos dizer que f(n) cresce tão rápido quanto uma função quadrática:
Podemos dizer que
f é Ω(N²), já que parac = 1 e N > 0vale
10*N² + 137*N + 15 > c*N2
Finalmente, o Θ-grande tem a ver com aproximações justas, quando o f e o g crescem no mesmo ritmo (exceto por um possível fator constante). A diferença do Θ-grande para o O-grande e o Ω-grande é que estes admitem aproximações folgadas, (por exemplo, N² ∈ O(N³)) em que uma das funções cresce muito mais rápida que a outra.
Dentre essas três notações, a mais comum de se ver é a do O-grande. Normalmente as análises de complexidade se preocupam apenas com o tempo de execução no pior caso então o limite superior dado pelo O-grande é suficiente.
Para algoritmos recursivos usa-se normalmente uma equação de recorrência[10] para se chegar á função de custo. Então, resolve-se essa equação de recorrência para se chegar à fórmula fechada da recorrência.
Muitas vezes é muito difícil se chegar a uma fórmula fechada, então usa-se outros métodos, como a árvore de recursão e o teorema-mestre[11] para se chegar à análise assintótica (usando a notação O-grande).

Notas de rodapé:
[1] Complexidade de tempo – Wikipédia, a enciclopédia livre
[2] Análise de Algoritmos
[3] Big O notation – Wikipedia
[4] Limit superior and limit inferior – Wikipedia
[5] Asymptotic notation
[6] Time complexity – Wikipedia
[7] Notação Big-θ (Grande-Theta)
[8] Grande-O – Wikipédia, a enciclopédia livre
[9] Notação Big-Ω (Grande-Omega)
[10] http://jeffe.cs.illinois.edu/teaching/algorithms/notes/99-recurrences.pdf
[11] Teorema mestre (análise de algoritmos) – Wikipédia, a enciclopédia livre
Essa foi a minha resposta no Quora à pergunta: “Como calcular o custo de um algoritmo”.
Link: https://pt.quora.com/Como-calcular-o-custo-de-um-algoritmo
quinta-feira, 23 julho, 2020 at 12:40 pm Deixe um comentário
Qual a utilidade da orientação a objetos na programação, se podemos simplesmente criar e reutilizar funções?
A maior vantagem da Orientação a Objetos é em prover um nível mais alto de Abstração de Dados e a construção e manutenção facilitada de Tipos Abstratos de Dados (TAD).
Não que isso não seja impossível com a programação estruturada (baseada em funções) – mas fazer e construir TAD’s assim, via programação estruturada é mais complicado e com manutenção mais difícil).
Na Orientação a Objetos o nível de abstração é muito maior e a construção de TAD’s (Tipos Abstratos de Dados) fica mais fácil e natural.
Você pode entender um Tipo Abstrato de Dados como uma expansão das capacidades naturais de uma Linguagem de Programação voltada à resolução de problemas reais. Um exemplo clássico é um tipo de dado racional (uma fração).
Originalmente, boa parte das implementações das linguagens de programação imperativas não oferecem esse tipo de dados de forma primitiva (pense em uma linguagem como C que tem 4 tipos de dados básicos ou primitivos: int, char, float e double). A questão de como representar uma fração racional (um número racional) é um problema.
Usamos, então, TAD’s para solucionar esse problema. Você pode pensar em TAD como uma especificação de um conjunto de dados aliado a algumas operações sobre esses dados. Conceitualmente, um tipo de dados (primitivo) da linguagem (como int ou float do C) também tem essa mesma definição: um range (uma faixa) de valores e um conjunto de operações. No caso do int, por exemplo, essa faixa (range) vai de -2.147.483.648 e 2.147.483.647 (que seriam 4 bytes -> 232232 ) e permite as operações de soma, subtração, multiplicação, divisão, incremento e decremento).
Então. Pense em um TAD como essa expansão que permite você representar coisas (abstrações) do mundo real no computador (uma máquina finita e com limitações de memória, hardware, etc.). Então um tipo de dados racional (uma fração) poderia ser definido e representado (em C) através de um tipo composto (um registro/estrutura) da seguinte maneira:
typedef struct {
float num; //seria o numerador da fração
float den; // obviamente o denominador
}Fracao; //o nome do novo tipo de dados
Mas, não esqueça, para abstrair tudo certinho o TAD precisa de operações, portanto, em seguida você fazer funções para criação, adição, subtração, multiplicação, divisão, MDC e quaisquer outras que fossem necessárias para complementar o TAD.
Normalmente se faz isso em C em mais de um arquivo, separando a definição do tipo, da sua interface (as suas funções). Isso funciona. Mas, dar manutenção nisso é bem complicado e quaisquer modificações exigiria alterar código em muitos lugares.
Agora pense nisso em um programa de milhares de linhas com centenas de TAD’s criados assim?
Na Orientação a Objetos tanto a abstração da realidade quanto a criação de TAD’s é simplificada no conceito de classe onde tanto a definição do tipo e as operações (as funções, que na OOP chamamos de métodos) estão todas juntas, como uma peça autônoma de código. Quando você altera qualquer comportamento (ou acrescenta ou retira atributos – propriedades) da classe (do tipo) isso é refletido imediatamente em todos os objetos criados a partir deste modelo (deste tipo).
Em uma linguagem Orientada a Objetos como Java, ou Python, ficaria tudo encapsulado/junto em um código só (em um arquivo só). Da seguinte forma (em Java):
class Fracao {
int num;
int den;
public Fracao(){ //construtor
//a regra da criação da fração viria aqui
//como não poder criar fração com den == 0
}
public adicao(Fracao y){
//código da soma
}
public subtração(Fracao y){
//código da soma
}
public multiplicação(Fracao y){
//código da soma
}
.... //quaisquer outros métodos ou operações
}
Então a resposta é basicamente essa: para fornecer um nível de abstração maior e de construção de TAD’s mais coeso, mais estruturado e mais funcional.
Além disso há a vantagem de representar o mundo real de forma mais semanticamente correta ou parecida (nível mais alto de abstração) e outras potencialidades como a reutilização de código via herança, interfaces, encapsulamento e polimorfismo.
Há desvantagens também. Não é uma panaceia e não resolve todos os problemas de programação do mundo. Mas, para sistemas grandes, complexos e com alto grau de manutenção ela é muito indicada.
Essa é a resposta que dei no site Quora a essa pergunta.
O link original da resposta é:
quinta-feira, 23 julho, 2020 at 11:31 am Deixe um comentário
Representando e descrevendo algoritmos…
Já sabemos o que é um algoritmo e com o que ele se parece, mas como representar os algoritmos? Como descrevê-los? Como podemos ter uma representação física ou “tangível” da ideia que o algoritmo representa e do problema que ele resolve?
Há, basicamente, 3 formas de se representar algoritmos:
- Representação descritiva (ou descrição narrativa).
- Fluxogramas.
- Pseudocódigo.
Há também uma quarta forma, mas essa é especial e falaremos dela depois.

A descrição narrativa (ou representação descritiva)
Bom, essa é a mais simples e menos formal de todas as formas de se representar um algoritmo. Consiste simplesmente de descrever ou narrar como o algoritmo funciona. Basicamente, serve para todos os tipos de algoritmos dada a sua generalidade. Exemplos:
Algoritmo para escovar os dentes:
- Pegar a escova de dentes e lavá-la.
- Pegar o tubo de creme dental .
- Abrir o tubo de creme dental.
- Apertar o tubo sobre a escova aplicando uma pequena quantidade de creme sobre a mesma.
- Fechar o tubo.
- Colocar a escova na boca e movimentá-la para a cima e para baixo em pequenos círculos por um determinado tempo (repetir esta operação até que os dentes estejam limpos)
- Enxaguar a boca.
- Limpar e guardar a escova.

Esse algoritmo é bem genérico e pouco específico. Interessante notar que cada linha tem um verbo no infinitivo, um comando, uma ação. Uma instrução.
Neste contexto algorítmico, uma instrução indica uma ação elementar a ser executada.
As características da Descrição Narrativa (ou representação descritiva) são:
- Uso da linguagem natural (no caso, Português);
- Facilidade para quem conhece a linguagem e as ações a serem executadas;
- Possibilidade de má interpretação, originando ambiguidades e imprecisões;
- Pouca confiabilidade (a imprecisão gera desconfiança);
- Extensão (se escreve muito para dizer pouco).
PARA EXERCITAR: Escrever algoritmos para trocar um pneu, fritar um ovo, trocar uma lâmpada, atravessar uma rua, tomar banho, calcular o dobro de um número, calcular a média do bimestre e descascar batatas.
Fluxogramas
Fluxograma é um diagrama que representa um processo ou um algoritmo passo a passo, descrevendo o fluxo do processo ou do algoritmo. Cada figura geométrica representa uma ação distinta. Esses diagramas ilustram, de forma simples, a sequência operacional do algoritmo (ou processo).
São usados para muito mais coisas do que descrever algoritmos ou processos de software. Alguns usos são:
- Workflow de processos de negócios;
- Diagrama de Fluxo de Dados (DFD) para modelagem e documentação de sistemas;
- Representação da lógica de um programa (ou algoritmo).
Exemplo de um fluxograma simples mostrando como lidar com uma lâmpada que não funciona (fonte: Wikipedia)

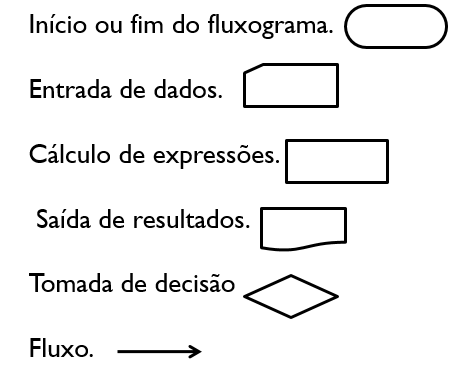
Principais figuras (existem dezenas de outras)
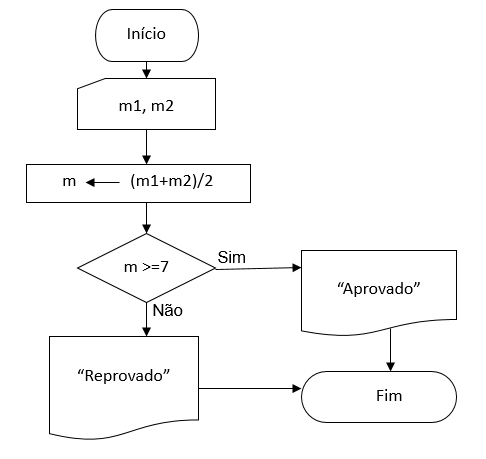
Exemplo (cálculo de uma média, dados duas notas)
Vantagens e desvantagens dos fluxogramas:
Vantagens:
- O fluxograma é uma das ferramentas mais conhecidas;
- Figuras dizem mais do que palavras; (rsrsrs)
- Padrão Mundial.
Desvantagens:
- A solução é amarrada a dispositivos físicos;
- Pouca atenção aos dados, não oferecendo recursos para descrevê-los ou representá-los coerentemente;
- Complicação à medida que o algoritmo cresce.
Bom, esse post já ficou muito grande, portanto a terceira forma, o pseudocódigo eu deixarei para o próximo post sobre essa seção de algoritmos!
Até!
E o algoritmo, hein? Afinal, que “bicho” é esse que domina o mundo?
Como o diminuto GPS consegue, tão rápido, em míseros segundos, achar uma rota para nós? Como o número do nosso cartão de crédito é protegido em uma transação virtual? Como as próprias transações virtuais são realizadas? Como conseguimos ouvir música e assistir a um vídeo, em nossos dispositivos eletrônicos de um local a quilômetros de distância de nós?
A resposta para essas e muitíssimas outras perguntas reside em uma palavra: algoritmo.
Mas, afinal, o que é um algoritmo?
Uma resposta genérica, rápida e de âmbito geral seria: “uma sequência de instruções que executadas ordenadamente e passo a passo, resolve um problema”. Aí você responde: com essa definição, então tudo é um algoritmo? Bom, …, quase tudo, mas, nem tudo! rsrsrs
Mas, sim, você executa algoritmos diariamente. Ao acordar, por exemplo, você escova os dentes. O procedimento de escovar os dentes é quase sempre o mesmo: abrir o tubo de creme dental, pegar a escova, apertar o tubo sobre a escova aplicando uma pequena quantidade de creme sobre a mesma, fechar o tubo, colocar a escova na boca e movimentá-la para a cima e para baixo em pequenos círculos por um determinado tempo, etc. Se você pega um ônibus para ir ao trabalho ou à escola também tem um algoritmo para isso e assim sucessivamente.
Mas, “peraí”, calma lá! Não são esses os algoritmos que executam as tarefas descritas no início do texto. Não, não são mesmo. Mas, eles partem do mesmo princípio.
Eu ensino sobre algoritmos há mais de dez anos e os alunos, invariavelmente acham difícil ou tem uma curva de aprendizado pouco suave (ao menos no início). Tratamos, neste blog, e no início do texto, dos algoritmos que podem ser executados em computadores, ou dispositivos de computação. E estes, simplesmente dominam o mundo…
Mas, vamos por partes (como nosso conhecido Jack). Os matemáticos conhecem o conceito de algoritmo (e de computação em geral) há muitos anos. É famoso, por exemplo, o método babilônico (ou algoritmo) para extração da raiz quadrada aproximada de um número (cerca de 2 mil anos antes de Cristo) e o muitíssimo conhecido Algoritmo de Euclides (300 a.C.) para a extração do MDC entre dois números.
Em suma, um algoritmo, de fato, representa um método para realizar uma tarefa. Os algoritmos de computador tem duas características principais (dentre tantas) que o distinguem de serem “métodos computacionais“: 1) Ele é não ambíguo e 2) tem que ter fim! (Um método para calcular o número π, por exemplo, grosso modo, não pode ser considerado um “algoritmo” formal, pois o número pi não tem fim! É um método. É computacional. Mas não tem fim!)
A consequência destas características é o que define, formalmente, algoritmo. O fato das instruções serem não ambíguas leva à corretude (entradas iguais geram saídas iguais), à previsão da saída e a finitude é o que leva uma máquina como o computador a executá-lo.
Normalmente, se exemplifica o conceito de algoritmo relacionando-o a uma receita culinária onde segue-se passos e usa-se ingredientes (dados de entrada) para gerar um prato (saída). É um exemplo comum e sua força reside na simplicidade da comparação.

Tecnicamente, pode-se repetir operações, efetuar cálculos e tomar decisões até que a tarefa seja completada. Diferentes algoritmos podem realizar a mesma tarefa usando instruções diferenciadas que levam mais ou menos tempo, espaço ou esforço computacional. Isso chama-se complexidade computacional e será estudado em outro tópico.
A precisão das instruções é crucial. Nós podemos tolerar algoritmos descritos imprecisamente, mas não o computador! Além de precisas, as instruções devem ser simples. Simples o bastante para uma máquina executar.
Basicamente, eu posso dizer para alguém: “pegue outra rua” quando o trânsito estiver engarrafado, mas não “dizer” o mesmo ao computador. Ele simplesmente não entenderia.
Portanto, chegamos a uma definição que pode-se dizer suficiente (embora informal):
“Algoritmos são sequências de instruções ou regras simples, ordenadas e que, se executadas passo a passo, a partir do início, resolvem um determinado problema em um tempo finito”.
Formalmente, a corretude de um algoritmo pode ser provada matematicamente e a análise de sua execução também (complexidade). Estas duas últimas tarefas são metas da Análise de Algoritmos. O conceito de algoritmo foi formalizado em 1936 por Alan Turing (pela máquina de Turing) e Alonzo Church (pelo cálculo lambda). Os dois conceitos formaram as fundações da Ciência da Computação.

O gênio, Alan Turing (1912-1954)
E eles estão em toda parte. Como eu disse anteriormente, dominam o mundo. Estão no carro quando se usa o GPS para se determinar uma rota de viagem (o aparelho executa os chamados algoritmos de “caminho mínimo“). Estão nas compras pela Internet garantindo a segurança de sites (algoritmos criptográficos). Estão por trás das entregas dos produtos determinando em qual ordem os caminhões devem seguir. São a base das rotas aeroviárias ditando o itinerário dos aviões comerciais e de logística. Estão dentro dos sistemas internos de usinas nucleares e servidores de páginas web como esta que você está lendo, enfim, eles estão sendo executados em computadores em todos os lugares, no notebook, em computadores de grande porte, em smartphones, em carros, TV’s, micro-ondas, enfim, em TODOS os lugares!
Não esqueça disso a próxima vez que marcar sua rota no GPS!
Ainda falaremos muito mais de algoritmos…
Até a próxima!
________________
P.S. o termo “algoritmo”, segundo Donald Knuth, provavelmente o maior cientista da computação vivo, é derivado do nome “al-Khowârizmî“, um matemático persa do século IX. A raiz da palavra, seu radical, é praticamente o mesmo de “álgebra”, “algarismo” e “logaritmo”.
😉
E a Probabilidade e a Estatística, hein?
Na faculdade eu sempre olhei muito enviesado para a Probabilidade e a Estatística, mas isso devia-se, claro, à ignorância em relação ao pensamento estatístico. Como Leonard Mlodinow nos ensina no excelente “O Andar do Bêbado: como o acaso determina nossas vidas“, e eu cito: “a mente humana foi construída para identificar uma causa definida para cada acontecimento, podendo assim ter bastante dificuldade em aceitar a influência de fatores aleatórios ou não relacionados”. É isso! Temos extrema dificuldade em entender o pensamento aleatório, probabilístico e, por consequência, o estatístico. Mas, como escrito no mesmo livro (citando o economista Armen Alchian), “os processos aleatórios são fundamentais na natureza, e onipresentes em nossa vida cotidiana; e ainda assim, a maioria das pessoas, não os compreende”.

Mas, é óbvio que isso precisa mudar. Nós, Cientistas da Computação e amantes da tecnologia e da Tecnologia da Informação em geral, não somos “a maioria das pessoas”. Precisamos mudar a nossa lógica determinística, afinal, a ciência inteira (e a Computação não fica de fora) é dominada inteiramente pela Estatística e pelo pensamento estocástico.
“O desenho de nossas vidas, como a chama da vela, é continuamente conduzido em novas direções por diversos eventos aleatórios que, juntamente com nossas reações a eles, determinam nosso destino. Como resultado, a vida é ao mesmo tempo difícil de prever e difícil de interpretar” – Leonard Mlodinow em “O Andar do Bêbado: como o acaso determina nossas vidas”
Portanto, começamos esse estudo, muitas vezes com resultados contra-intuitivos. Mas temos uma ferramenta de grande valia: o computador e as linguagens de programação. Portanto, vamos começar com um experimento básico: a probabilidade da moeda lançada.
Para isso, fiz um script em Python (2.7.11) para simular o lançamento de uma moeda e, em seguida, computar as probabilidades dos lançamentos. Os resultados são interessantes. Quanto mais o número de lançamentos aumenta mais as frequências aproximam-se do número previsto (50% para cada uma das faces).
Aqui está o código:
# -*- coding: UTF-8 -*-
"""
Função:
Exemplo de lançamento de moeda
Autor:
Professor Ed - Data: 29/05/2016 -
Observações: ?
"""
def gera_matriz_lancamentos(matriz, tamanho):
import random
matriz_faces = []
print 'Gerando...'
for x in range(tamanho):
num = random.randint(1,2) #1 = cara, 2 = coroa
matriz.append (num)
if num==1:
matriz_faces.append('Cara')
else:
matriz_faces.append('Coroa')
print matriz_faces
def calcula_probabilidades(matriz, tamanho):
soma_cara = 0
soma_coroa = 0
for i in range(len(matriz)):
if matriz[i]==1:
soma_cara = soma_cara+1
elif matriz[i]==2:
soma_coroa = soma_coroa + 1
probabilidade_cara = float(soma_cara)/float(tamanho)*100
probabilidade_coroa = float(soma_coroa)/float(tamanho)*100
print 'Foram lancadas ' + str(soma_cara) + ' caras e ' + str(soma_coroa) + ' coroas'
probabilidades = []
probabilidades.append(probabilidade_cara)
probabilidades.append(probabilidade_coroa)
return probabilidades
matriz=[]
tamanho = int(raw_input('Digite o tamanho da matriz de lancamentos: '))
gera_matriz_lancamentos(matriz, tamanho)
#print 'Um para cara e 2 para coroa'
#print matriz
vetor_probabilidades = []
vetor_probabilidades = calcula_probabilidades(matriz, tamanho)
print 'As probabilidades sao: %f%% e %f%%' % (vetor_probabilidades[0], vetor_probabilidades[1])
Nem sempre, como os números gerados pelo computador são (pseudo)aleatórios (falaremos disto depois), as frequências são próximas a 50% (variando bastante entre as execuções do programa), mas, em geral, sempre que a quantidade de lançamentos é imensa (acima de 10.000), as probabilidades aproximam-se do limite esperado.
Lembrando, sempre, que se lançarmos uma moeda um milhão de vezes não deveríamos esperar um placar exato (50% caras e 50% coroas). A teoria das probabilidades nos fornece uma medida do tamanho da diferença (chamada de erro) que pode existir neste experimento de um processo aleatório. Se ma moeda for lançada, digamos, N vezes, haverá um distanciamento (erro) de aproximadamente 1/2 N “caras”, este erro, de fato, pode ser para um lado ou para o outro. Ou seja, espera-se que, em “moedas honestas“, o erro seja da ordem da raiz quadrada de N.
Assim, digamos que de cada 1.000.000 lançamentos de uma moeda honesta, o número de caras se encontrará, provavelmente entre 499.000 e 501.000 (já que 1.000 é a raiz quadrada de N). Para moedas viciadas, espera-se que o erro seja consistentemente maior que a raiz quadrada de N.
 Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Um exemplo da execução do programa com duas instâncias exatamente iguais, mas com valores gerados diferentes. (mais ou menos como acontece na realidade).
Abaixo, um exemplo de uma instância com 100.000 lançamentos provando que as frequências, de fato, aproximam-se das probabilidades previstas (inclusive se considerado o erro):

Segundo a Lei dos Grandes Números, a média aritmética dos resultados da realização da mesma experiência repetidas vezes tende a se aproximar do valor esperado à medida que mais tentativas se sucederem. E, claro, se todos os eventos tiverem igual probabilidade o valor esperado é a média aritmética. (Lembrando, claro, que o valor em si, não pode ser “esperado” no sentido geral, o que leva à uma falácia). Ou seja, quanto mais tentativas são realizadas, mais a probabilidade da média aritmética dos resultados observados se aproximam da probabilidade real.
A Probabilidade é descrita por todos, alunos, professores e estudantes, como difícil. Em minha opinião, ela dá a impressão de ser difícil porque muitas vezes, desafia nosso senso comum (que, normalmente, tende sempre à falácia do apostador, ou de Monte Carlo), ainda mais quando dispomos do conhecimento da lei dos grandes números. Estratégias como “o dobro ou nada” nadam de braçadas no inconsciente coletivo com esta falácia.
O teorema de Bayes (que é um corolário da Lei da Probabilidade Total) explica direitinho o porque da falácia do apostador ser, bem, …, uma falácia. Sendo a moeda honesta, os resultados em diferentes lançamentos são estatisticamente independentes e a probabilidade de ter cara em um único lançamento é exatamente 1⁄2.
É isso aí. Nos próximos posts vamos falar um pouco mais sobre os significados e como calcular essas probabilidades, sempre tentando um enfoque prático com a ajuda dessa ferramenta magnífica que é o computador!
Até!
P.S.: Assim que meu repositório for clonado certinho (tive uns problemas com o Git local) eu coloco o link para o programa prontinho no Github.
Pronto! Já apanhei resolvi o problema do Git e você pode baixar o arquivo-fonte clicando aqui.
P.S.1: Acabei não resistindo e fazendo o teste para 1.000.000 de lançamentos. O resultado está aqui embaixo. Confira:

Popularidade de linguagens – Você conhece o índice Tiobe?
Você conhece ou já ouviu falar do índice Tiobe? Este é um ranking organizado pela empresa Tiobe que tenta mostrar a popularidade das linguagens de programação quando comparada com outras. Ele iniciou em 2001 e é atualizado todos os meses desde então.
Ele leva em consideração o número de resultados de buscas de nomes de linguagens ou equivalentes em inúmeros sites como Google, Wikipedia, YouTube, Yahoo, Bing, Amazon, Blogger, Baidu e WordPress.
Há uma antiga amiga dos estudantes de Estruturas de Dados que, desde o início do ranking, praticamente nunca saiu do top 5. Nem preciso dizer que é a boa e velha filha de Dennis Ritchie, a Linguagem C!
O ranking de Julho de 2013 estava assim (para as 10 primeiras posições):
| Position Jul 2013 | Position Jul 2012 | Delta in Position | Programming Language | Ratings Jul 2013 | Delta Jul 2012 | Status |
|---|---|---|---|---|---|---|
| 1 | 1 |  |
C | 17.628% | -0.70% | A |
| 2 | 2 | |
Java | 15.906% | -0.18% | A |
| 3 | 3 | |
Objective-C | 10.248% | +0.91% | A |
| 4 | 4 | |
C++ | 8.749% | -0.37% | A |
| 5 | 7 |  |
PHP | 7.186% | +2.17% | A |
| 6 | 5 |  |
C# | 6.212% | -0.46% | A |
| 7 | 6 | |
(Visual) Basic | 4.336% | -1.36% | A |
| 8 | 8 | |
Python | 4.035% | +0.03% | A |
| 9 | 9 | |
Perl | 2.148% | +0.10% | A |
| 10 | 11 | |
JavaScript | 1.844% | +0.39% | A |
Neste agosto de 2013 ela (a Linguagem C) deu uma variada e caiu para 2º lugar por alguns décimos. Confira:
| Position Aug 2013 | Position Aug 2012 | Delta in Position | Programming Language | Ratings Aug 2013 | Delta Aug 2012 | Status |
|---|---|---|---|---|---|---|
| 1 | 2 | |
Java | 15.978% | -0.37% | A |
| 2 | 1 | |
C | 15.974% | -2.96% | A |
| 3 | 4 | |
C++ | 9.371% | +0.04% | A |
| 4 | 3 | |
Objective-C | 8.082% | -1.46% | A |
| 5 | 6 | |
PHP | 6.694% | +1.17% | A |
| 6 | 5 | |
C# | 6.117% | -0.47% | A |
| 7 | 7 | |
(Visual) Basic | 3.873% | -1.46% | A |
| 8 | 8 | |
Python | 3.603% | -0.27% | A |
| 9 | 11 | |
JavaScript | 2.093% | +0.73% | A |
| 10 | 10 | |
Ruby | 2.067% | +0.38% | A |
O que confirma a força da linguagem criada há mais de quarenta anos nos laboratórios da Bell para desenvolver o Unix. Maior do que a popularidade é a influência da rainha das linguagens de programação. Praticamente todas as linguagens foram, de alguma forma (umas mais, outras menos) influenciada por C. Praticamente existe uma divisão em A.C. e D.C. (Antes de C e Depois de C) na história das linguagens de programação!
Só por curiosidade, o LangPop coloca a linguagem C como a número 1 em popularidade em suas séries. Confira: http://www.langpop.com/
O que você acha deste índice de popularidade? É confiável? Concorda que C é um marco na história das linguagens de programação? Quais as linguagens que você utiliza? Gosta de C? Sabe C? Comente! 🙂
quarta-feira, 14 agosto, 2013 at 10:10 am Deixe um comentário
Aulas de Fundamentos de Programação e Algoritmos (04, 05 e 06) e Exercício – 50 Algoritmos
Caros alunos de Fundamentos de Programação e Algoritmos. Seguem as aulas 04, 05 e 06 além do exercício maravilhoso dos 50 algoritmos! Para baixar é só clicar.
Fund. de Programação e Algoritmos – Aula 04
Fund. de Programação e Algoritmos – Aula 05
Fund. de Programação e Algoritmos – Aula 06
Exercícios de Algoritmos (50 Algoritmos).
Não esqueçam que as apresentações dos trabalhos começam nesta semana (dia 22/06), portanto, estejam preparados!
Bons estudos!
Aulas de Estruturas de Dados (03, 04, 05 e 06)
Aqui estão disponíveis as aulas 03, 04, 05 e 06 de Estruturas de Dados e seus respectivos exercícios (inseridos nas próprias aulas). As datas de entrega dos exercícios foram comentadas somente em sala de aula. Curtam e estudem. (Lembrando que o material de Estruturas de Dados em C está reduzido pelo pouco tempo disponível devido a troca de professores). Para baixar é só clicar:
Estruturas de Dados – Aula 03
Estruturas de Dados – Aula 04
Estruturas de Dados – Aula 05
Estruturas de Dados – Aula 06
Bons estudos!
Aula 03 e lista de exercícios 03 de Fundamentos de Programação e Algoritmos
Caros alunos de Fundamentos de Programação e Algoritmos, segue a lista de exercícios 03 e a aula 03.
Não esqueçam que só a prática leva à perfeição. O sucesso é construído com esforço e dedicação.
Um grande Abraço!
Aula 02 de Estrutura de Dados e questões sobre a primalidade de inteiros
Já está disponível a AULA 02 de Estrutura de Dados. Para baixar, basta clicar aqui.
Lembrando que retirei o slide que continha o programa com o teste de primalidade, já que ele deverá ser enviado como trabalho até dia 26/04, quinta-feira. Após este período colocarei a aula completa, lembrando que como comentei este teste de primalidade é extremamente ineficiente.
Sobre a questão de primalidade de números inteiros, recomendadíssimo a leitura sobre o teste de primalidade AKS, conhecido como teste da primalidade Agrawal-Kayal-Saxena. E também o teste de primalidade de Fermat para geração de números não-primos ou mesmo o teste de primalidade de Miller-Rabin (que é probabilístico).
Para entender de verdade os (fascinantes) números primos, recomendo, para quem está com tempo, a leitura deste trabalho.
Um abs.
Depois volto aqui e posto sobre os números primos com questões relacionadas aos algoritmos para obtê-los e toda a mística que os envolvem.
Até mais.
(P.S. – Um pequeno desafio a meus alunos – bem fácil, diga-se – é implementar em C o algoritmo do teste de primalidade AKS e me enviar!)
Aulas e Listas de Exercícios de Estrutura de Dados e de Fundamentos de Programação e Algoritmos
Caros alunos. Desculpem pela demora (de 1 dia) para postar as aulas e as listas de exercícios.
A turma de Estrutura de Dados está ainda na Lista de exercícios 01. Para baixá-la clique aqui. Não esqueçam de acrescentar os 10 programas escritos em sala de aula que estão no slide 53 da Aula 01. Para baixar a Aula 01 Completa e Revisada (versão 2.0), clique aqui.
A turma de Fundamentos de Programação e Algoritmos já está na lista de exercícios 02. Para baixá-la, clique aqui. Para baixar o conteúdo completo da Aula 02, clique aqui. Para baixar as Notas da Aula 02 basta clicar aqui.
A data máxima para entrega de ambas as listas é dia 20/04/2012, próxima sexta-feira, portanto, não se atrasem. Aproveitem o fim de semana para resolver todos os exercícios. Qualquer dúvida, basta contatar o professor. Abs e até a próxima semana.
Volta às aulas com Fundamentos de Programação e Algoritmos
Bom, depois de conhecer a turma de Estrutura de Dados, hoje foi a vez da turma 21620112 de Sistemas de Informação, 2º. período da disciplina Fundamentos de Programação e Algoritmos. A aula, a apresentação com os alunos e dos alunos e a passagem do conteúdo foram bem divertidas e interessantes. Turma grande, 56 alunos, porém dinâmica e participativa o que facilita o trabalho do professor. Apresentações, plano de aula, metodologia, avaliação e a primeira aula foram proveitosas e até o último tópico (e isso foi às 22:08). Agradeço a turma pela paciência pelo extrapolamento do horário(e por ficarem até o final) e também pela grande participação e interesse na disciplina. Espero ter deixado claro o quanto esta disciplina é importante para o restante do curso. Teremos pouco tempo, mas tenho certeza que serão ótimos momentos. Um abraço a todos.
Link para o arquivo da Aula 01: clique aqui.
Link para Ementa/plano de curso e conteúdo programático da disciplina: clique aqui.
Link para as notas de aula da Aula 01: clique aqui.
É recomendadíssimo que o arquivo seja baixado, lido estudado e resolvido. Lembrando que as informações estão resumidas e que as explicações em sala foram, sem dúvida, essenciais.
Link para o programa Visualg. Clique aqui.
Mais links sobre algoritmos aqui, aqui e aqui.
P.S.: Todos os emails que me foram passados na lista já devem ter recebido o convite para acesso à pasta compartilhada no DropBox. Quem não recebeu, comenta aqui ou me contacte por outro meio confirmando seu email para que eu possa reenviar o pedido.
Até!
Volta às aulas com Estrutura de Dados
A primeira aula com a turma de Sistemas de Informação, 3º. Período.Turma 21620111, disciplina Estrutura de Dados foi proveitosa. Apresentações, plano de aula, metodologia, avaliação e introdução à disciplina de forma bem tranquila e simpática por parte dos alunos. Agradeço também à recepção, ao bom humor e à oportunidade de ministrar conteúdo tão importante para a formação profissional. Um abraço a todos.
Link para o arquivo da primeira parte da Aula 01: clique aqui
Link para o FAQ de carreiras da Blizzard citado na aula (e que mostra que C/C++ anda vivíssimo): http://us.blizzard.com/pt-br/company/careers/faq.html
Por que estudar C/C++? http://cpp.drgibbs.com.br/home/porque-estudar-c
Link do CodeBlocks: http://sourceforge.net/projects/codeblocks/files/Binaries/10.05/Windows/codeblocks-10.05mingw-setup.exe
Link do Dev-C++: http://www.baixaki.com.br/download/dev-c-.htm
É caros amigos, voltei à sala de aula, este ambiente onde me sinto tão à vontade. Por caminhos estranhos me foi dada a oportunidade de ensinar programação em C aos jovens pupilos do Curso de Sistemas de Informação da Uninorte. A primeira disciplina será Algoritmos e Linguagens de Programação e a segunda, a de hoje, Estrutura de Dados. Fiquei, de certa forma, feliz, pois quem me conhece sabe o quanto amo a sala de aula, a oportunidade de ensinar e aprender com o dia-a-dia dos alunos. Conhecer pessoas e ajudá-las a trilhar o caminho profissional que tanto almejam, isso sim, como diz certo comercial, não tem preço. Um abraço e amanhã tem mais.
segunda-feira, 2 abril, 2012 at 11:50 pm Deixe um comentário
A Matemática de tudo
Quando disse para um amigo meu do trabalho que iria fazer uma apresentação sobre Matemática para alunos do ensino médio ele (não sei porque) ficou intrigado. “Como pode uma apresentação de Matemática”, ele retrucou. Fiquei a madrugada preparando o material que iria fazer parte da Semana de Matemática da Escola KJK (Kairala José Kairala que, por acaso, foi onde cursei o ensino médio!). Comecei por volta das 11 horas e, felizmente, 45 minutos depois, às 11:45 TODOS os alunos e alunas ainda estavam no auditório quente (sem ar condicionado naquele dia) viajando com os devaneios e maravilhas da Matemática
Compartilho agora esta apresentação que fiz para pouco mais de 200 alunos do ensino médio do KJK na semana de #matemática de 2010: Chama-se “A matemática de tudo”.
Fui à escola à pedido do professor de filosofia Edmilson Lima que, por acaso, é meu pai (e hoje, 30/05, comemora meio século de vida \o/). A apresentação mostra o quanto estamos rodeados de matemática por todos os lados e demonstra que sem ela jamais estaríamos no atual estado tecnológico e científico que nos encontramos…
Link: http://www.slideshare.net/edkallenn/a-matemtica-de-tudo-edkallenn-lima ou então clique aqui.
“A matemática é o alfabeto pelo qual Deus criou o universo” – Galileu Galilei.
P.S. Uma pena os vídeos não puderem ser compartilhadas, mas prometo que os posto no Youtube e depois volto aqui e atualizo este post com os links. Abs.
Material de Auditoria de Sistemas
Postando (atrasado!!, sorry class!) o material de Auditoria de SISTEMAS. Aula 01 e Aula 02.
Até!


Comentários